import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pandas_datareader as pdr
import seaborn as sns
import statsmodels.formula.api as smf
import yfinance as yfHerron Topic 3 - Practice for Section 04
FINA 6333 for Spring 2024
1 Announcements
- We will make a few changes to give us more time to work on Project 3:
- We will drop Herron Topic 5 on simulations during Week 14 and use this time for group work
- I will finalize Project 3 by Thursday, 4/4, so we have about 3 week to work on it before the Tuesday, 4/23, due date
- Next Thursday and Friday, 4/11 and 4/12, we will take the MSFQ assessment exam in class. I do not control this exam, and there are a few conditions:
- Open book
- On Canvas
- In the classroom
2 10-Minute Recap
- The Capital Asset Pricing Model (CAPM) estimates asset \(i\)’s expected return as \(E(r_i) = r_f + \beta_i [E(r_M) - r_f]\), where:
- \(r_f\) is the risk-free rate
- \(\beta_i\) is asset \(i\)’s systematic risk
- \(E(r_M) - r_f\) is the market risk premium
- The Security Market Line (SML) visualizes the CAPM
- Plots \(E(r_i)\) on the y axis against \(\beta_i\) on the x axis
- The slope of the SML is the market risk premium \(E(r_M) - r_f\)
- The intercept of the SML is the risk-free rate \(r_f\)
- We can estimate asset \(i\)’s systematic risk a few ways:
- \(\beta_i = \frac{Cov(r_i-r_f, r_M-r_f)}{Var(r_M-r_f)}\)
- \(\beta_i = Corr(r_i-r_f, r_M-r_f) \frac{Std(r_i-r_f)}{Std(r_M-r_f)}\)
- Estimate the linear regression \(r_i - r_f = \alpha_i + \beta_i [r_M - r_f] + \varepsilon_i\) with the
smf.ols()function after weimport statsmodels.formula.api as smf - We will follow Bodie, Kane, and Marcus’s syntax where a \(r\) is a raw return and a \(R\) is an excess return, so \(R_i = r_i - r_f\)
- The CAPM is the foundation of modern finance and does well for single periods but has a few shortcomings:
- Does poorly over multiple periods
- The SML is “too flat” empirically, and high \(\beta\) assets tend to have lower returns than expected
- Does explain the returns on several factors, like size, value, and momentum
- The Fama-French 3-factor model—and many others—attempts to solves these shortcomings and is useful for evaluating fund manager performance
3 Practice
%precision 4
pd.options.display.float_format = '{:.4f}'.format
%config InlineBackend.figure_format = 'retina'3.1 Plot the security market line (SML) for a variety of asset classes
Use the past three years of daily data for the following exhange traded funds (ETFs):
- SPY (SPDR—Standard and Poor’s Depository Receipts—ETF for the S&P 500 index)
- BIL (SPDR ETF for 1-3 month Treasury bills)
- GLD (SPDR ETF for gold)
- JNK (SPDR ETF for high-yield debt)
- MDY (SPDR ETF for S&P 400 mid-cap index)
- SLY (SPDR ETF for S&P 600 small-cap index)
- SPBO (SPDR ETF for corporate bonds)
- SPMB (SPDR ETF for mortgage-backed securities)
- SPTL (SPDR ETF for long-term Treasury bonds)
tickers = 'SPY BIL GLD JNK MDY SLY SPBO SPMB SPTL'For multifactor models, we generally leave returns in percents. Slope coefficient estimates (i.e., \(\beta\)s) are the same for decimal and percent returns. Intercept coefficient estimates (i.e., \(\alpha\)s) are easier to interpret in percents than in decimals because small percent returns have two fewer zeros than small decimal returns.
etf = (
yf.download(tickers=tickers)
['Adj Close']
.iloc[:-1]
.pct_change()
.mul(100)
)
etf.tail()[*********************100%%**********************] 9 of 9 completed
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1015031953.py:5: FutureWarning: The default fill_method='pad' in DataFrame.pct_change is deprecated and will be removed in a future version. Either fill in any non-leading NA values prior to calling pct_change or specify 'fill_method=None' to not fill NA values.
.pct_change()| BIL | GLD | JNK | MDY | SLY | SPBO | SPMB | SPTL | SPY | |
|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||
| 2024-03-28 | 0.0000 | 1.2900 | -0.1573 | 0.3589 | 0.0000 | -0.0687 | -0.2297 | 0.0000 | -0.0191 |
| 2024-04-01 | 0.0273 | 1.0208 | -0.4974 | -0.7225 | 0.0000 | -0.7728 | -0.7249 | -1.8024 | -0.1740 |
| 2024-04-02 | 0.0219 | 1.4772 | -0.1910 | -1.2799 | 0.0000 | -0.1391 | -0.0930 | -0.4022 | -0.6358 |
| 2024-04-03 | 0.0000 | 0.8772 | 0.0532 | 0.3998 | 0.0000 | 0.0696 | 0.0466 | -0.1101 | 0.1099 |
| 2024-04-04 | 0.0437 | -0.5735 | -0.1382 | -1.0594 | 0.0000 | 0.1392 | 0.3257 | 0.6983 | -1.2206 |
ff = (
pdr.DataReader(
name='F-F_Research_Data_Factors_daily',
data_source='famafrench',
start='1900'
)
[0]
)
ff.tail()C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\3487692931.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(| Mkt-RF | SMB | HML | RF | |
|---|---|---|---|---|
| Date | ||||
| 2024-02-23 | 0.0200 | 0.2800 | -0.0300 | 0.0210 |
| 2024-02-26 | -0.2600 | 1.0000 | -0.1100 | 0.0210 |
| 2024-02-27 | 0.2700 | 1.1900 | -0.4500 | 0.0210 |
| 2024-02-28 | -0.2600 | -0.8500 | 0.0000 | 0.0210 |
| 2024-02-29 | 0.5400 | -0.3400 | 0.9800 | 0.0210 |
We will write two helper functions to make it easier to calculate annualized mean returns and CAPM betas. We will pass these function names to the pandas .agg() method, which applies these functions to every column and combines the results.
def calc_ann_mean(ri, ann_fac=252):
return ri.mean() * ann_facetf.apply(calc_ann_mean)BIL 0.9715
GLD 9.6202
JNK 5.2090
MDY 12.9373
SLY 9.4062
SPBO 3.3207
SPMB 2.1316
SPTL 4.4217
SPY 11.4856
dtype: float64def calc_beta(ri, rf=ff['RF'], RM=ff['Mkt-RF']):
# betai = Cov(Ri, RM) / Var(RM)
Ri = ri.sub(rf).dropna()
return Ri.cov(RM) / RM.loc[Ri.index].var()etf.apply(calc_beta)BIL -0.0030
GLD 0.0475
JNK 0.3547
MDY 1.0540
SLY 1.0626
SPBO 0.0468
SPMB 0.0522
SPTL -0.2212
SPY 0.9819
dtype: float64We should estimate CAPM betas from one-year to three-years of daily returns.
etf_sml = (
etf
.loc['2021-02':'2024-01']
.agg([calc_ann_mean, calc_beta])
.transpose()
)etf_sml = (
etf
.loc['2021-02':'2024-01']
.agg([calc_ann_mean, calc_beta])
.transpose()
)The regplot() function in the seaborn package plots a scatterplot and adds a best-fit line with 95% confidence interval.
sns.regplot(
data=etf_sml,
x='calc_beta',
y='calc_ann_mean'
)
for t, (x, y) in etf_sml[['calc_beta', 'calc_ann_mean']].iterrows():
plt.annotate(text=t, xy=(x, y))
plt.ylabel('Annualized Mean of Daily Returns (%)')
plt.xlabel(r'Capital Asset Pricing Model (CAPM) $\beta$')
plt.title(
'Security Market Line (SML) from Exchange Traded Funds (ETFs)\n' +
'Daily Returns from 2021-02 to 2024-01'
)
plt.show()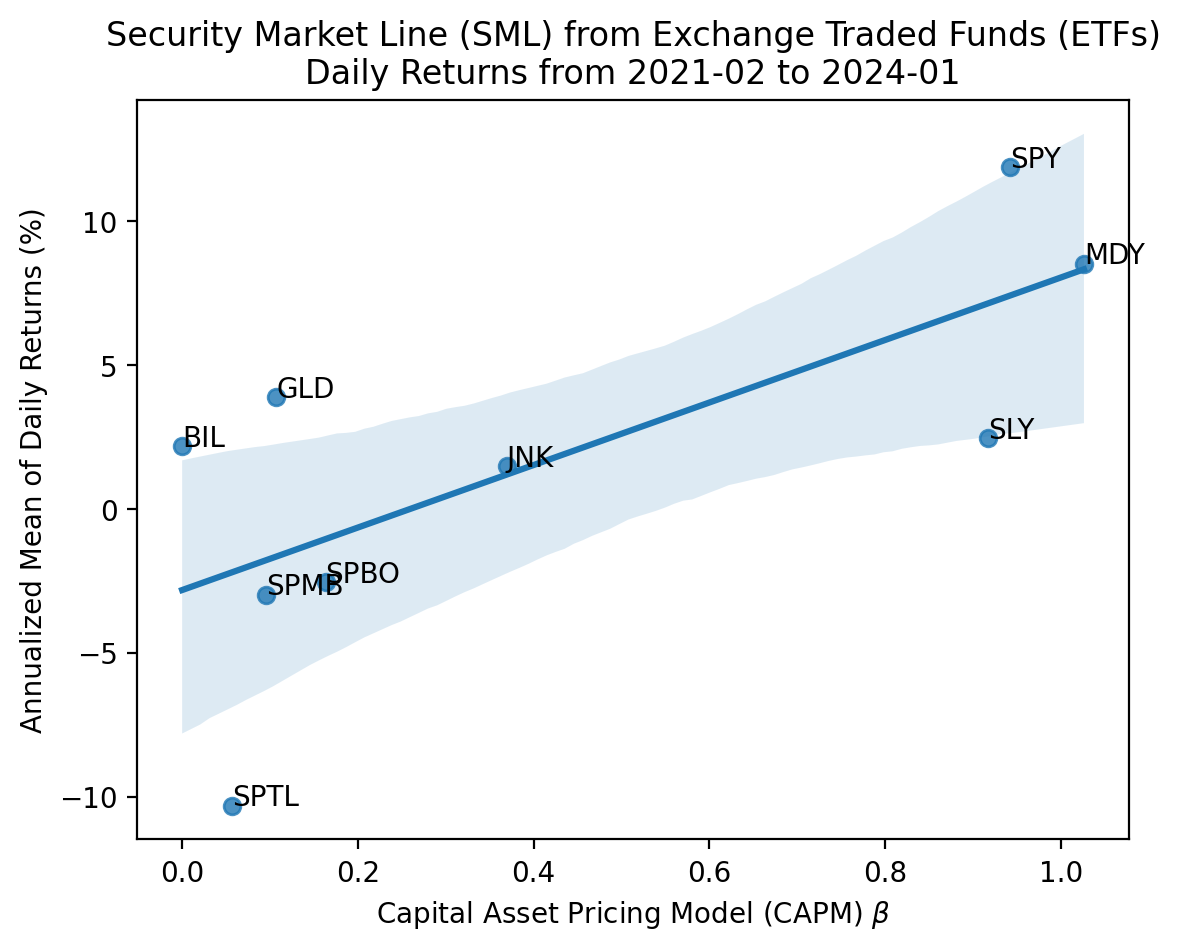
We see the CAPM and SML work well for asset classes! The slope is positive, the intercept is a reasonable risk-free rate, and assets plot along the SML, most within the 95% confidence interval. Note that a few fixed-income ETFs have negative mean returns, but the SML still has the shape and fit we expect by theory.
The fit above is not perfect, but the \(R^2\) is fairly high at around 50%. For a single-factor regression, we can quickly calculate \(R^2\) as \(\rho^2\).
etf_sml.corr().loc['calc_ann_mean', 'calc_beta']**20.5086smf.ols(formula='calc_ann_mean ~ calc_beta', data=etf_sml).fit().rsquared0.50863.2 Plot the SML for the Dow Jones Industrial Average (DJIA) stocks
Use the past three years of daily returns data for the stocks listed on the DJIA Wikipedia page. Compare the DJIA SML to the asset class SML above.
tickers = (
pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
[1]
['Symbol']
.to_list()
)djia = (
yf.download(tickers=tickers)
['Adj Close']
.iloc[:-1]
.pct_change()
.mul(100)
)
djia.tail()[*********************100%%**********************] 30 of 30 completed| AAPL | AMGN | AMZN | AXP | BA | CAT | CRM | CSCO | CVX | DIS | ... | MMM | MRK | MSFT | NKE | PG | TRV | UNH | V | VZ | WMT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 2024-03-28 | -1.0559 | -0.6916 | 0.3058 | -0.0263 | 0.5418 | 0.4881 | -0.0664 | 0.2813 | 0.8890 | 1.1407 | ... | 1.4150 | 0.1518 | -0.1685 | -0.1593 | -0.2214 | 0.5725 | 0.3245 | 0.0215 | 1.0111 | -0.9058 |
| 2024-04-01 | -0.8456 | -0.4502 | 0.3271 | -0.0351 | -1.8084 | -0.7341 | 0.3586 | 0.2605 | 0.8495 | -0.6783 | ... | 6.0129 | -0.7275 | 0.9151 | -1.5110 | -1.0293 | -0.8603 | -1.0107 | -0.2867 | 0.7626 | -0.2825 |
| 2024-04-02 | -0.6999 | -2.4131 | -0.1547 | -0.9138 | -0.7705 | 0.2997 | 0.5757 | -1.3589 | 0.4400 | 1.0615 | ... | -1.2551 | -0.4886 | -0.7372 | -1.7394 | -0.0062 | -0.1359 | -6.4448 | 0.0575 | 0.6150 | -1.4000 |
| 2024-04-03 | 0.4797 | -0.6480 | 0.9519 | 0.4877 | -1.6592 | 3.0041 | 0.2434 | -0.4493 | 0.4131 | -3.1265 | ... | 0.3770 | -0.3452 | -0.2349 | -0.6817 | -2.7527 | 0.5310 | 0.3492 | -0.5315 | 0.7052 | 0.4564 |
| 2024-04-04 | -0.4892 | -2.3067 | -1.3212 | -2.8062 | -0.8815 | -1.5966 | -3.4784 | -1.2926 | 0.1558 | -1.5885 | ... | -2.8437 | -1.7244 | -0.6113 | -1.3949 | -0.4483 | -0.2445 | -0.9484 | -1.0687 | -0.9104 | 0.1178 |
5 rows × 30 columns
djia_sml = (
djia
.loc['2021-02':'2024-01']
.agg([calc_ann_mean, calc_beta])
.transpose()
)sns.regplot(
data=djia_sml,
x='calc_beta',
y='calc_ann_mean'
)
for t, (x, y) in djia_sml[['calc_beta', 'calc_ann_mean']].iterrows():
plt.annotate(text=t, xy=(x, y))
plt.ylabel('Annualized Mean of Daily Returns (%)')
plt.xlabel(r'Capital Asset Pricing Model (CAPM) $\beta$')
plt.title(
'Security Market Line (SML) from Dow-Jones Stocks\n' +
'Daily Returns from 2021-02 to 2024-01'
)
plt.show()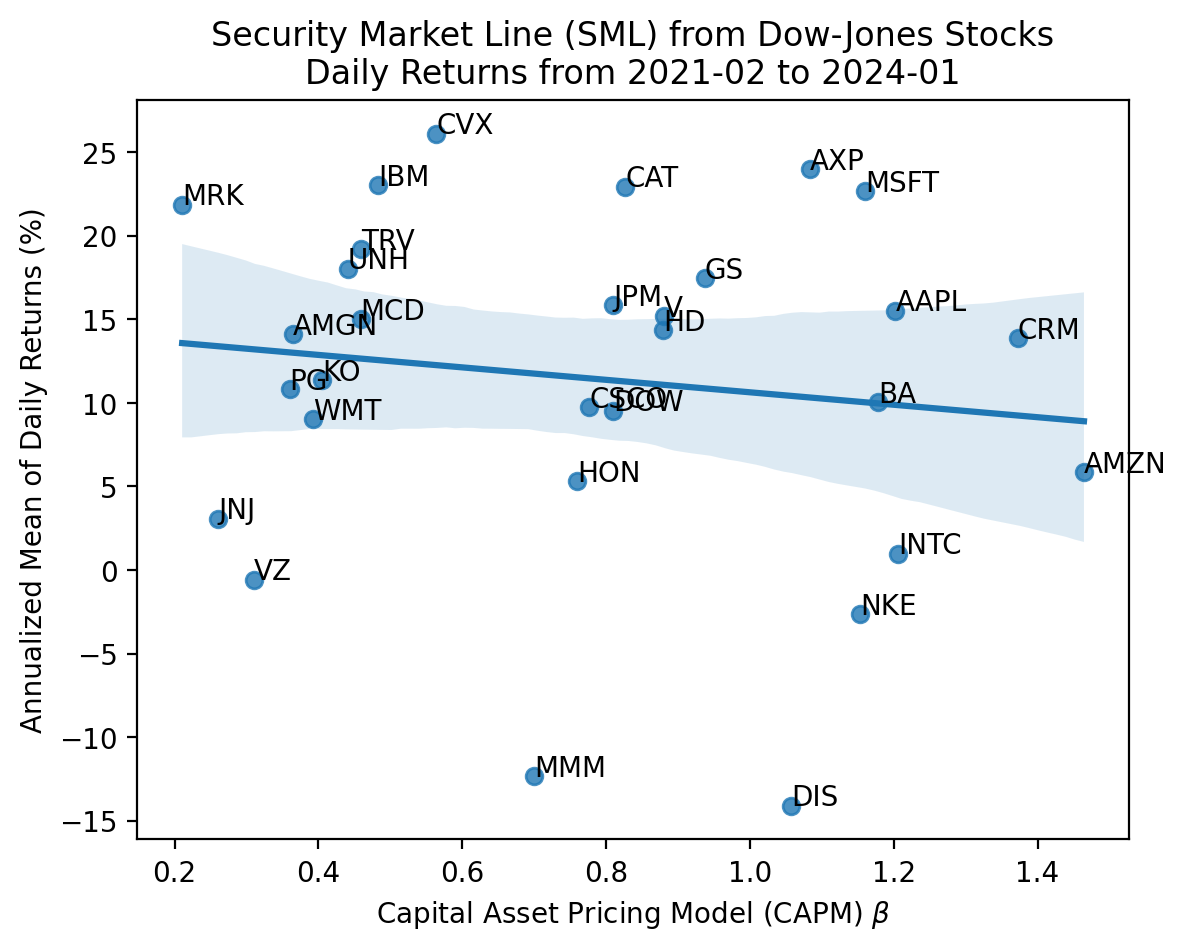
For single stocks the SML falls apart!
- The slope is negative and we would fail to reject it is flat
- The intercept is above the risk-free rate
- Many stocks plot outside the 95% confidence interval
djia_sml.corr().loc['calc_ann_mean', 'calc_beta']**20.0178smf.ols(formula='calc_ann_mean ~ calc_beta', data=djia_sml).fit().rsquared0.01783.3 Plot the SML for the five portfolios formed on beta
Download data for portfolios formed on \(\beta\) (Portfolios_Formed_on_BETA) from Ken French. For the value-weighted portfolios, plot realized returns versus \(\beta\). These data should elements [2] and [6], respectively.
ff_beta = (
pdr.DataReader(
name='Portfolios_Formed_on_BETA',
data_source='famafrench',
start='1900'
)
)
print(ff_beta['DESCR'])Portfolios Formed on BETA
-------------------------
This file was created by CMPT_BETA_RETS using the 202402 CRSP database. It contains value- and equal-weighted returns for portfolios formed on BETA. The portfolios are constructed at the end of June. Beta is estimated using monthly returns for the past 60 months (requiring at least 24 months with non-missing returns). Beta is estimated using the Scholes-Williams method. Annual returns are from January to December. Missing data are indicated by -99.99 or -999. The break points include utilities and include financials. The portfolios include utilities and include financials. Copyright 2024 Kenneth R. French
0 : Value Weighted Returns -- Monthly (728 rows x 15 cols)
1 : Equal Weighted Returns -- Monthly (728 rows x 15 cols)
2 : Value Weighted Returns -- Annual from January to December (60 rows x 15 cols)
3 : Equal Weighted Returns -- Annual from January to December (60 rows x 15 cols)
4 : Number of Firms in Portfolios (728 rows x 15 cols)
5 : Average Firm Size (728 rows x 15 cols)
6 : Value-Weighted Average of Prior Beta (61 rows x 15 cols)C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\530606425.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(ff_beta_sml = (
ff_beta[2].iloc[:, :5] # annual value-weighted returns on quintile portfolios
.stack() # convert to long data frame with one column of returns
.to_frame('Return')
.join(
ff_beta[6].iloc[:, :5] # value-weighted betas from previous year on quintile portfolios
.stack() # convert to long data frame with one column of betas
.to_frame('Beta')
)
.rename_axis(
index=['Data', 'Portfolio'],
columns='Variable'
)
)
ff_beta_sml.tail()| Variable | Return | Beta | |
|---|---|---|---|
| Data | Portfolio | ||
| 2023 | Lo 20 | 2.3000 | 0.3950 |
| Qnt 2 | 27.9500 | 0.8710 | |
| Qnt 3 | 26.2600 | 1.1630 | |
| Qnt 4 | 44.3900 | 1.5190 | |
| Hi 20 | 74.7900 | 2.1440 |
start = ff_beta_sml.index.get_level_values(0).year[0]
stop = ff_beta_sml.index.get_level_values(0).year[-1]
sns.regplot(
data=ff_beta_sml,
x='Beta',
y='Return'
)
plt.ylabel('Annual Return (%)')
plt.xlabel(r'Capital Asset Pricing Model (CAPM) $\beta$')
plt.title(
r'Security Market Line (SML) for $\beta$ Quintile Portfolios' +
f'\nfor Annual Returns from {start} to {stop}'
)
plt.show()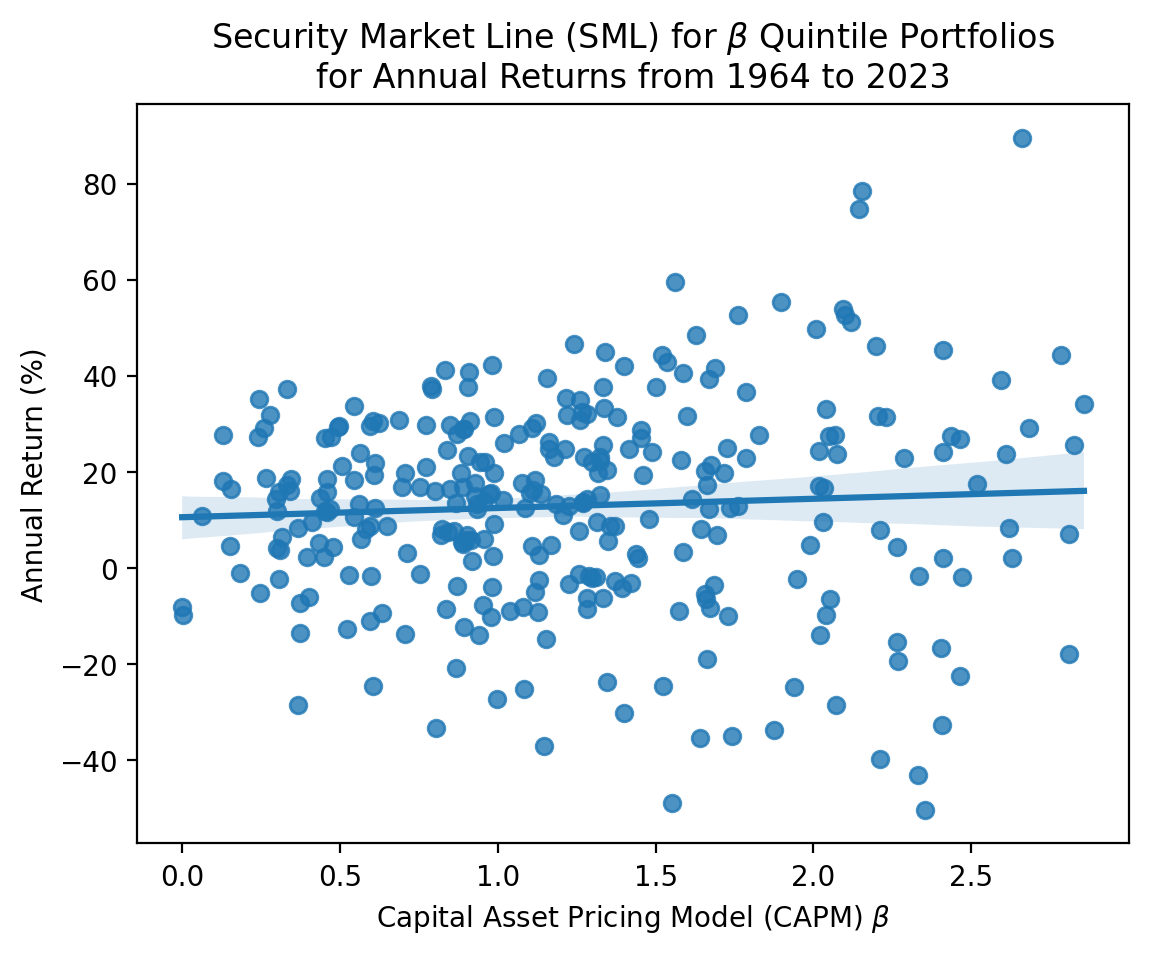
3.4 Estimate the CAPM \(\beta\)s on several levered and inverse exchange traded funds (ETFs)
Try the following ETFs:
- SPY
- UPRO
- SPXU
Can you determine what these products do from the data alone? Estimate \(\beta\)s and plot cumulative returns. You may want to pick short periods of time with large market swings.
etf_2 = (
yf.download(tickers='SPY UPRO SPXU')
.rename_axis(columns=['Variable', 'Ticker'])
['Adj Close']
.iloc[:-1]
.pct_change()
.mul(100)
.dropna()
)[*********************100%%**********************] 3 of 3 completedetf_2.apply(calc_beta).rename(r'$\beta$')Ticker
SPXU -2.8635
SPY 0.9582
UPRO 2.8790
Name: $\beta$, dtype: float64start = etf_2.index[0]
stop = etf_2.index[-1]
etf_2.apply(calc_beta).plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel(r'Capital Asset Pricing Model (CAPM) $\beta$')
plt.title(
r'Capital Asset Pricing Model (CAPM) $\beta$s' +
f'\nfrom Daily Returns from {start:%b %d %Y} to {stop:%b %d %Y}'
)
plt.show()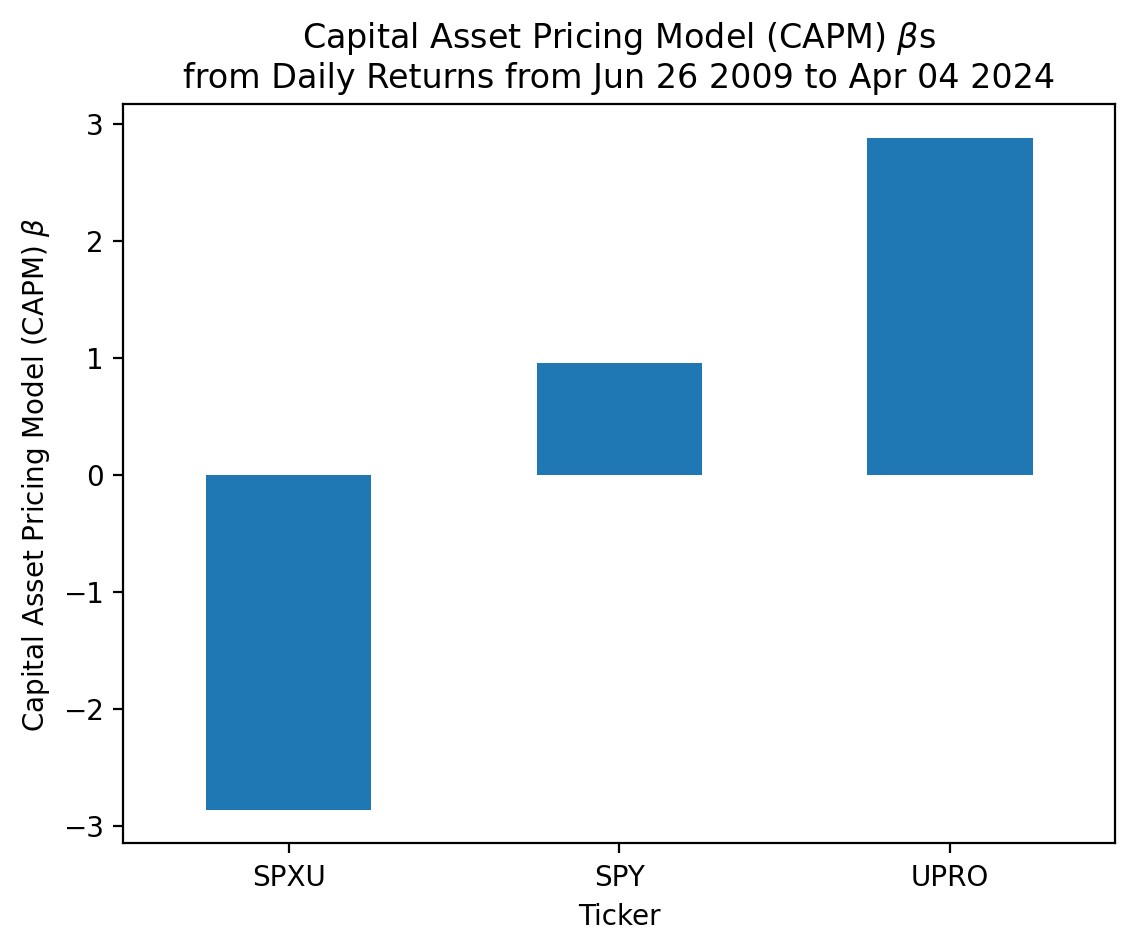
3.5 Explore the size factor
First, we need data for portfolio and factor returns.
ff_me = (
pdr.DataReader(
name='Portfolios_Formed_on_ME',
data_source='famafrench',
start='1900'
)
)
print(ff_me['DESCR'])Portfolios Formed on ME
-----------------------
This file was created by CMPT_ME_RETS using the 202402 CRSP database. It contains value- and equal-weighted returns for size portfolios. Each record contains returns for: Negative (not used) 30% 40% 30% 5 Quintiles 10 Deciles The portfolios are constructed at the end of Jun. The annual returns are from January to December. Missing data are indicated by -99.99 or -999. Copyright 2024 Kenneth R. French
0 : Value Weight Returns -- Monthly (1172 rows x 19 cols)
1 : Equal Weight Returns -- Monthly (1172 rows x 19 cols)
2 : Value Weight Returns -- Annual from January to December (97 rows x 19 cols)
3 : Equal Weight Returns -- Annual from January to December (97 rows x 19 cols)
4 : Number of Firms in Portfolios (1172 rows x 19 cols)
5 : Average Firm Size (1172 rows x 19 cols)C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\4020728382.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(ff_m = (
pdr.DataReader(
name='F-F_Research_Data_Factors',
data_source='famafrench',
start='1900'
)
)
print(ff_m['DESCR'])F-F Research Data Factors
-------------------------
This file was created by CMPT_ME_BEME_RETS using the 202402 CRSP database. The 1-month TBill return is from Ibbotson and Associates, Inc. Copyright 2024 Kenneth R. French
0 : (1172 rows x 4 cols)
1 : Annual Factors: January-December (97 rows x 4 cols)C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\772652417.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\772652417.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(df_me = (
ff_me[1]
.iloc[:, -10:]
.join(ff_m[0])
)
df_me.tail()| Lo 10 | Dec 2 | Dec 3 | Dec 4 | Dec 5 | Dec 6 | Dec 7 | Dec 8 | Dec 9 | Hi 10 | Mkt-RF | SMB | HML | RF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||
| 2023-10 | -9.3900 | -8.4100 | -7.9700 | -7.5300 | -6.4900 | -5.5100 | -6.4000 | -6.3600 | -4.6000 | -2.2600 | -3.1900 | -3.8700 | 0.1900 | 0.4700 |
| 2023-11 | 6.3000 | 9.0500 | 9.5800 | 9.6400 | 11.8700 | 9.6700 | 9.8400 | 9.6400 | 9.9900 | 9.2700 | 8.8400 | -0.0200 | 1.6400 | 0.4400 |
| 2023-12 | 10.8700 | 17.2700 | 14.4800 | 14.2400 | 13.1200 | 12.0000 | 9.1600 | 9.6500 | 7.0000 | 5.5400 | 4.8700 | 6.3400 | 4.9300 | 0.4300 |
| 2024-01 | -2.8200 | -5.4600 | -5.8600 | -4.9400 | -5.0700 | -3.1900 | -2.3800 | -1.2600 | -1.7100 | 1.5900 | 0.7100 | -5.0900 | -2.3800 | 0.4700 |
| 2024-02 | 5.5400 | 6.7100 | 4.8000 | 8.1900 | 3.4200 | 4.4400 | 6.3100 | 4.5400 | 5.7900 | 3.7100 | 5.0600 | -0.2400 | -3.4800 | 0.4200 |
3.5.1 Estimate \(\alpha\)s for the ten portfolios formed on size
Academics started researching size-based portfolios in the early 1980s, so you may want to focus on the pre-1980 sample.
mod = smf.ols(
formula='I(Q("Lo 10") - RF) ~ Q("Mkt-RF")',
data=df_me.loc[:'1980']
)
fit = mod.fit()
fit.summary()| Dep. Variable: | I(Q("Lo 10") - RF) | R-squared: | 0.541 |
| Model: | OLS | Adj. R-squared: | 0.540 |
| Method: | Least Squares | F-statistic: | 767.6 |
| Date: | Fri, 05 Apr 2024 | Prob (F-statistic): | 2.92e-112 |
| Time: | 17:46:28 | Log-Likelihood: | -2343.5 |
| No. Observations: | 654 | AIC: | 4691. |
| Df Residuals: | 652 | BIC: | 4700. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
| Intercept | 0.9161 | 0.343 | 2.669 | 0.008 | 0.242 | 1.590 |
| Q("Mkt-RF") | 1.5976 | 0.058 | 27.706 | 0.000 | 1.484 | 1.711 |
| Omnibus: | 626.765 | Durbin-Watson: | 1.970 |
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 28924.644 |
| Skew: | 4.226 | Prob(JB): | 0.00 |
| Kurtosis: | 34.464 | Cond. No. | 5.99 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Now, we can use list comprehensions to quickly estimate all ten \(\alpha\)s.
ports = df_me.columns.to_list()[:10]mods = [
smf.ols(formula=f'I(Q("{p}") - RF) ~ Q("Mkt-RF")', data=df_me.loc['1994':])
for p
in ports
]
fits = [m.fit() for m in mods]params = (
pd.concat([f.params for f in fits], axis=1, keys=ports, names='Portolio')
.transpose()
)bses = (
pd.concat([f.bse for f in fits], axis=1, keys=ports, names='Portfolio')
.transpose()
)start = df_me.loc[:'1980'].index[0].to_timestamp()
stop = df_me.loc[:'1980'].index[-1].to_timestamp()
params['Intercept'].plot(kind='bar', yerr=bses['Intercept'])
plt.ylabel(r'Monthly CAPM $\alpha$ (%)')
plt.xticks(rotation=0)
plt.title(
r'Size Portfolio Monthly CAPM $\alpha$s' +
'\n' +
f'from {start:%b %Y} through {stop:%b %Y}'
)
plt.show()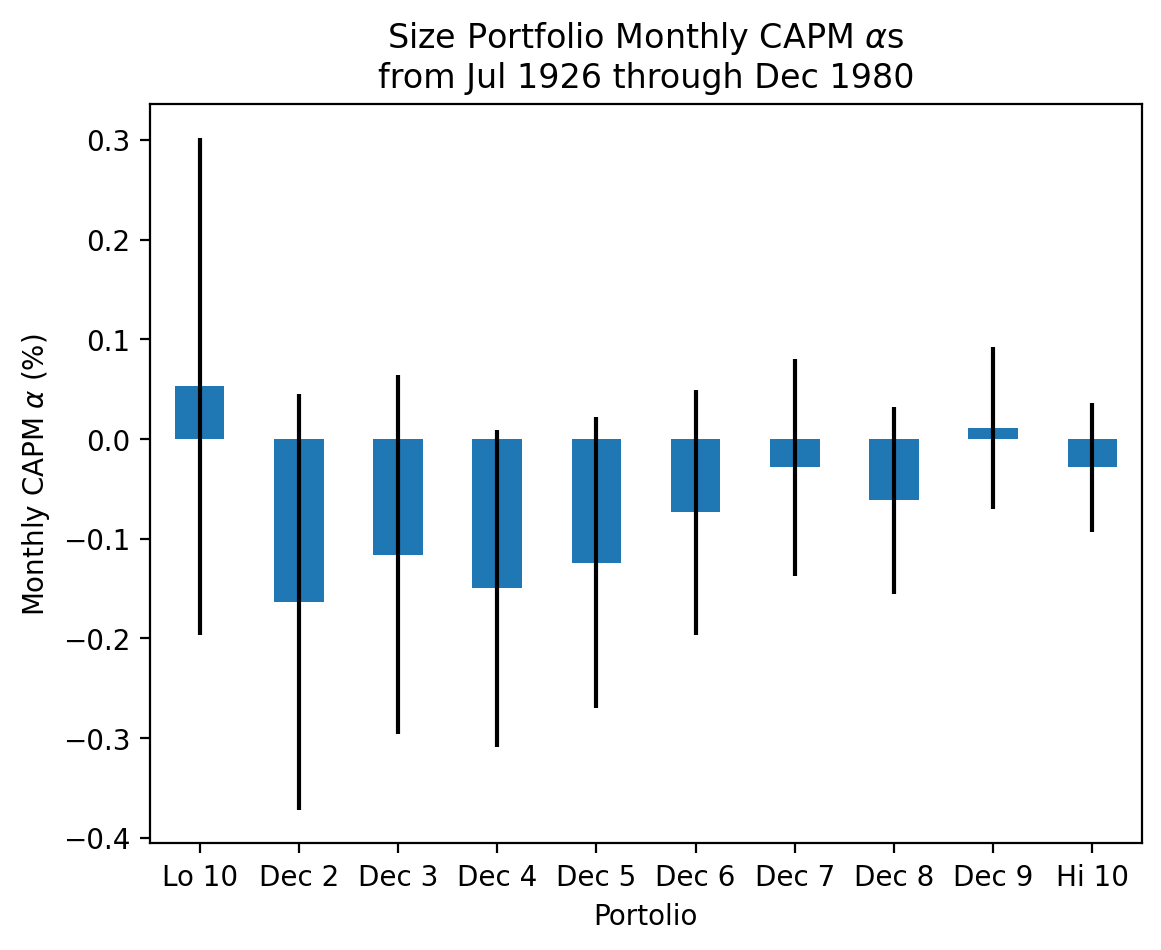
3.5.2 Are the returns on these ten portfolios formed on size concentrated in a specific month?
df_me_2 = (
ff_me[0]
.iloc[:, -10:]
.stack()
.rename_axis(index=['Date', 'Portfolio'])
.to_frame('Return')
.reset_index()
.assign(Month=lambda x: np.where(x['Date'].dt.month==1, 'January', 'Not January'))
)sns.barplot(
data=df_me_2,
x='Month',
y='Return',
hue='Portfolio'
)
plt.ylabel('Mean Monthly Return (%)')
plt.title('When Do We Earn Size-Effect Returns?')
plt.show()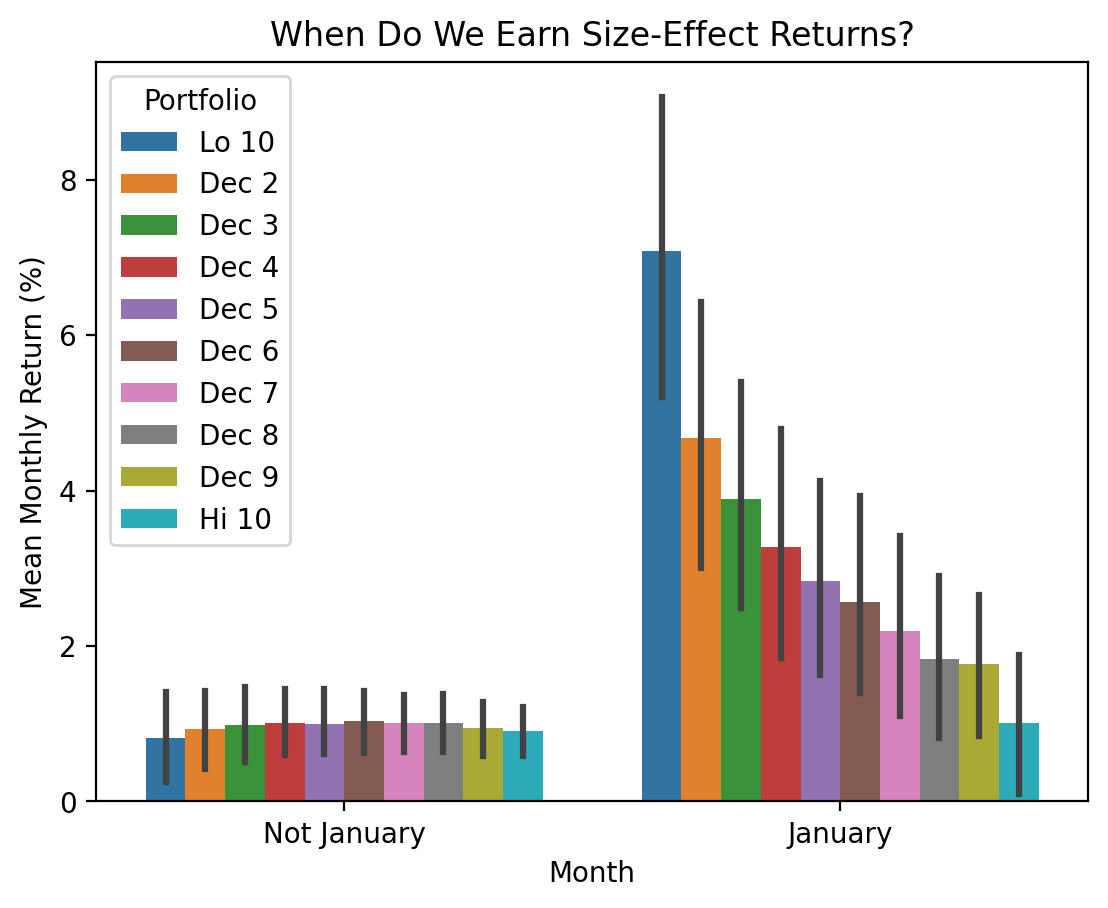
3.5.3 Compare the size factor to the market factor
You may want to consider mean excess returns by decade. The market and size excess returns are factors Mkt-RF and SMB in the Fama-French factors data.
df_me_3 = (
ff_m[0]
[['Mkt-RF', 'SMB']]
.stack()
.rename_axis(index=['Date', 'Factor'])
.to_frame('Return')
.reset_index()
.assign(Decade=lambda x: (x['Date'].dt.year // 10 ) * 10)
)sns.barplot(
data=df_me_3,
x='Decade',
y='Return',
hue='Factor'
)
plt.ylabel('Annualized Mean of Monthly Returns (%)')
plt.title('Comparison on Market and Small Stock Risk Premia')
plt.show()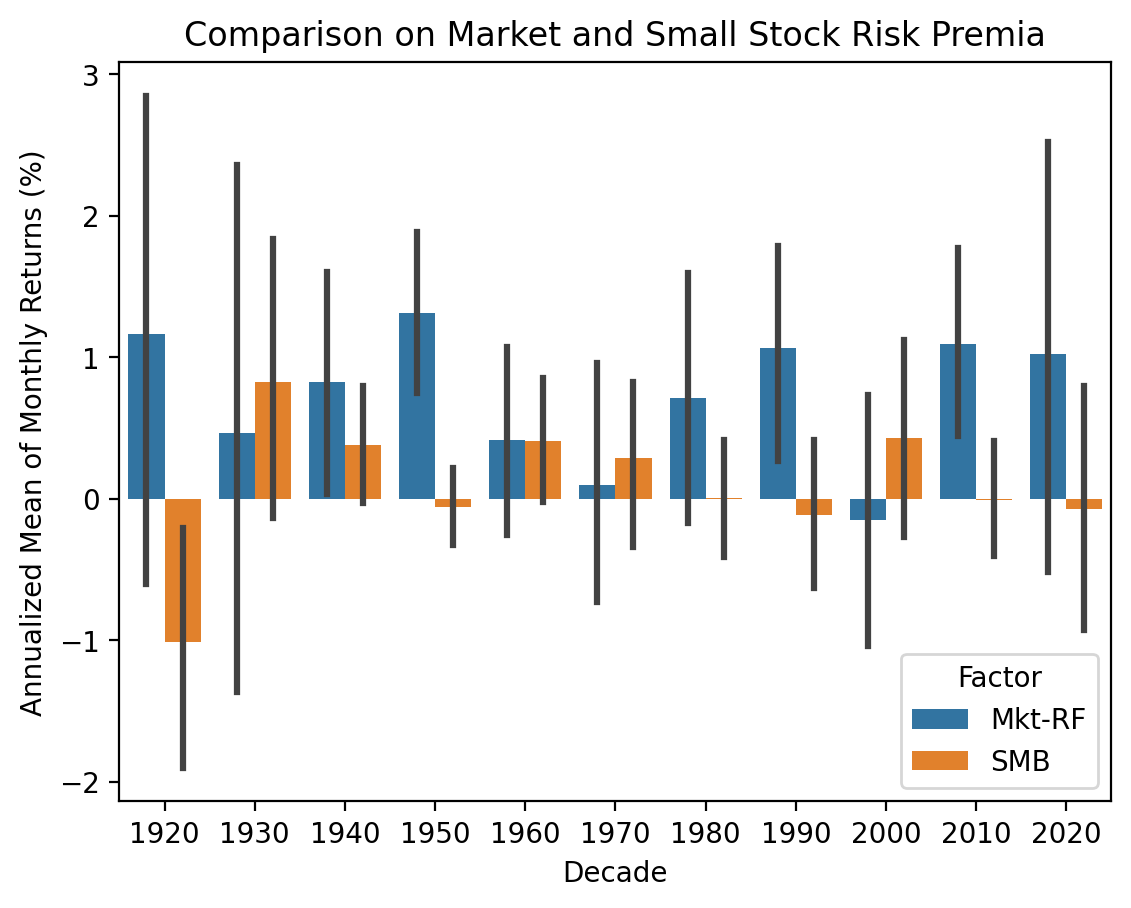
SMB rarely generates outsize returns later in the sample.
3.6 Repeat the exercises above with the value factor
ff_be_me = pdr.DataReader(
name='Portfolios_Formed_on_BE-ME',
data_source='famafrench',
start='1900'
)C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1841624243.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_be_me = pdr.DataReader(print(ff_me['DESCR'])Portfolios Formed on ME
-----------------------
This file was created by CMPT_ME_RETS using the 202402 CRSP database. It contains value- and equal-weighted returns for size portfolios. Each record contains returns for: Negative (not used) 30% 40% 30% 5 Quintiles 10 Deciles The portfolios are constructed at the end of Jun. The annual returns are from January to December. Missing data are indicated by -99.99 or -999. Copyright 2024 Kenneth R. French
0 : Value Weight Returns -- Monthly (1172 rows x 19 cols)
1 : Equal Weight Returns -- Monthly (1172 rows x 19 cols)
2 : Value Weight Returns -- Annual from January to December (97 rows x 19 cols)
3 : Equal Weight Returns -- Annual from January to December (97 rows x 19 cols)
4 : Number of Firms in Portfolios (1172 rows x 19 cols)
5 : Average Firm Size (1172 rows x 19 cols)df_be_me = (
ff_be_me[1]
.iloc[:, -10:]
.join(ff_m[0])
)
df_be_me.tail()| Lo 10 | Dec 2 | Dec 3 | Dec 4 | Dec 5 | Dec 6 | Dec 7 | Dec 8 | Dec 9 | Hi 10 | Mkt-RF | SMB | HML | RF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||
| 2023-10 | -7.6200 | -6.5300 | -8.4300 | -7.7500 | -7.0200 | -7.0800 | -6.1800 | -7.0600 | -7.6800 | -8.4300 | -3.1900 | -3.8700 | 0.1900 | 0.4700 |
| 2023-11 | 9.8800 | 9.8900 | 8.5700 | 7.1800 | 11.5300 | 13.6400 | 8.7100 | 10.5800 | 6.4300 | 6.6500 | 8.8400 | -0.0200 | 1.6400 | 0.4400 |
| 2023-12 | 9.8700 | 9.2100 | 15.0800 | 11.0000 | 9.7200 | 11.9100 | 14.2700 | 14.1400 | 13.9600 | 13.2000 | 4.8700 | 6.3400 | 4.9300 | 0.4300 |
| 2024-01 | -4.0000 | -1.3500 | -3.4800 | -3.2100 | -4.5000 | -3.5100 | -3.3800 | -4.4200 | -3.6400 | -0.4200 | 0.7100 | -5.0900 | -2.3800 | 0.4700 |
| 2024-02 | 6.1900 | 7.6000 | 7.2500 | 5.2900 | 7.5200 | 7.6200 | 3.3800 | 3.3400 | 1.7400 | 7.2900 | 5.0600 | -0.2400 | -3.4800 | 0.4200 |
ports = df_be_me.columns.to_list()[:10]mods = [
smf.ols(formula=f'I(Q("{p}") - RF) ~ Q("Mkt-RF")', data=df_be_me)
for
p in ports
]fits = [m.fit() for m in mods]params = (
pd.concat([f.params for f in fits], axis=1, keys=ports, names='Portolio')
.transpose()
)bses = (
pd.concat([f.bse for f in fits], axis=1, keys=ports, names='Portfolio')
.transpose()
)start = df_be_me.index[0].to_timestamp()
stop = df_be_me.index[-1].to_timestamp()
params['Intercept'].plot(kind='bar', yerr=bses['Intercept'])
plt.ylabel(r'Monthly CAPM $\alpha$ (%)')
plt.xticks(rotation=0)
plt.title(
r'BE/ME Portfolio Monthly CAPM $\alpha$s' +
'\n' +
f'from {start:%b %Y} through {stop:%b %Y}'
)
plt.show()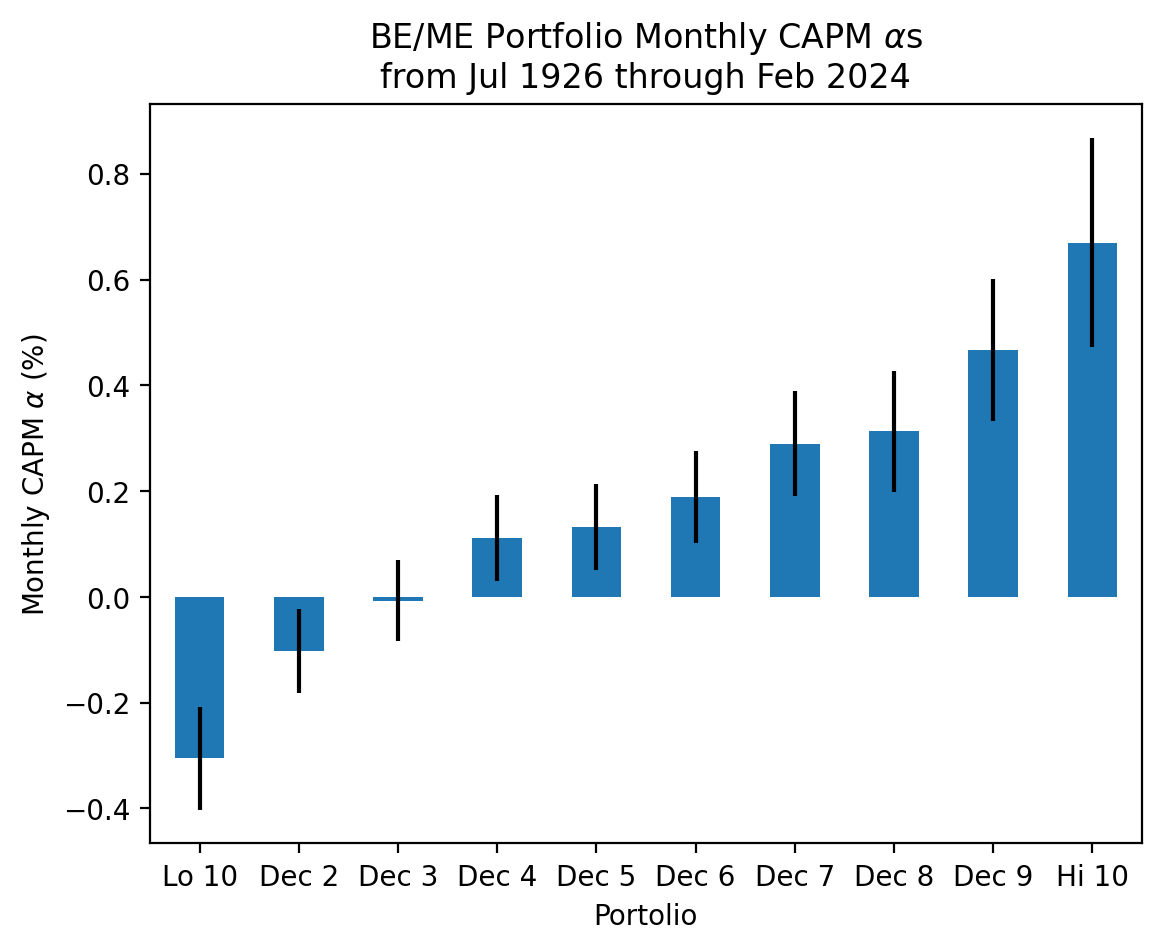
df_be_me_3 = (
ff_m[0]
[['Mkt-RF', 'HML']]
.stack()
.rename_axis(index=['Date', 'Factor'])
.to_frame('Return')
.reset_index()
.assign(Decade=lambda x: (x['Date'].dt.year // 10 ) * 10)
)sns.barplot(
data=df_be_me_3,
x='Decade',
y='Return',
hue='Factor'
)
plt.ylabel('Annualized Mean of Monthly Returns (%)')
plt.title('Comparison on Market and Value Stock Risk Premia')
plt.show()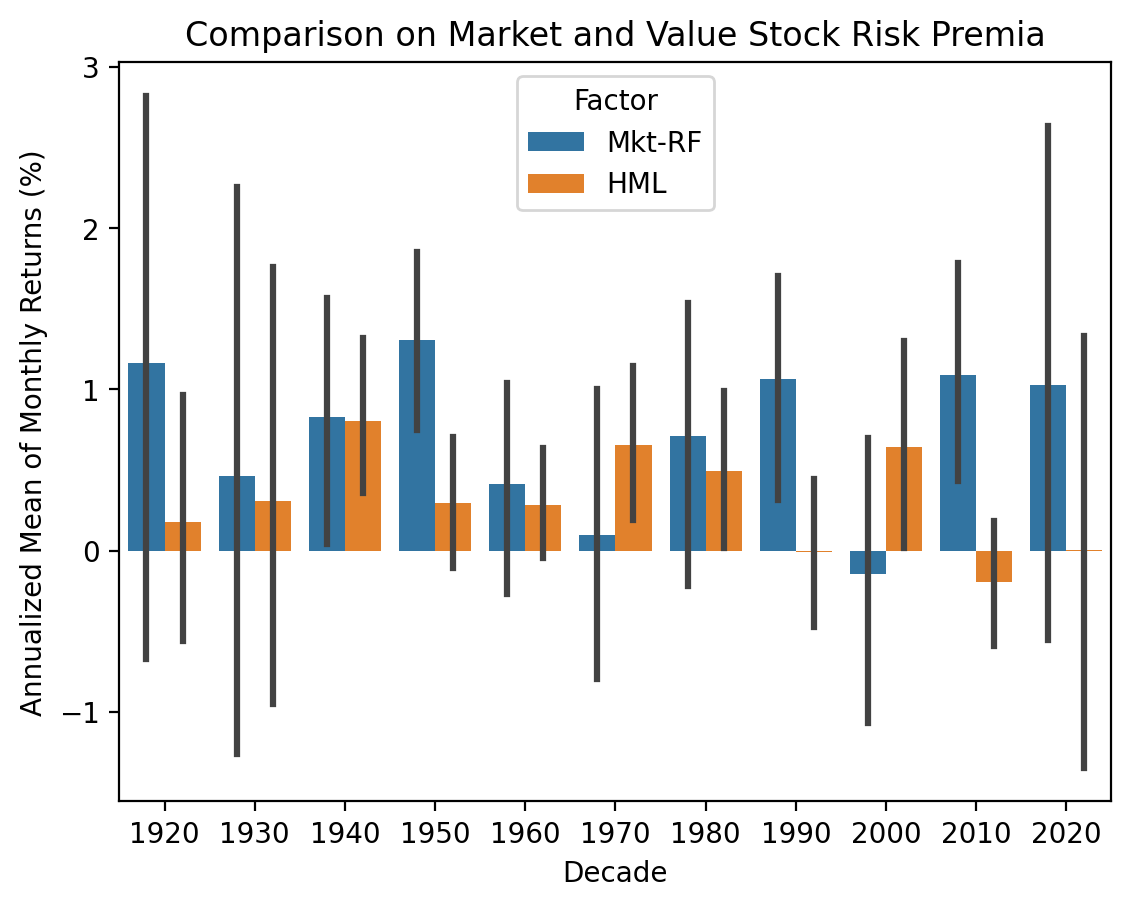
3.7 Repeat the exercises above with the momentum factor
You may find it helpful to consider the worst months and years for the momentum factor.
ff_mom = pdr.DataReader(
name='10_Portfolios_Prior_12_2',
data_source='famafrench',
start='1900'
)C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2097656781.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(print(ff_mom['DESCR'])10 Portfolios Prior 12 2
------------------------
This file was created by CMPT_PRIOR_RETS using the 202402 CRSP database. It contains value- and equal-weighted returns for 10 prior-return portfolios. The portfolios are constructed monthly. PRIOR_RET is from -12 to - 2. The annual returns are from January to December. Missing data are indicated by -99.99 or -999.
0 : Average Value Weighted Returns -- Monthly (1166 rows x 10 cols)
1 : Average Equal Weighted Returns -- Monthly (1166 rows x 10 cols)
2 : Average Value Weighted Returns -- Annual (97 rows x 10 cols)
3 : Average Equal Weighted Returns -- Annual (97 rows x 10 cols)
4 : Number of Firms in Portfolios (1166 rows x 10 cols)
5 : Average Firm Size (1166 rows x 10 cols)
6 : Value-Weighted Average of Prior Returns (97 rows x 10 cols)df_mom = (
ff_mom[1]
.iloc[:, -10:]
.join(ff_m[0])
)
df_mom.tail()| Lo PRIOR | PRIOR 2 | PRIOR 3 | PRIOR 4 | PRIOR 5 | PRIOR 6 | PRIOR 7 | PRIOR 8 | PRIOR 9 | Hi PRIOR | Mkt-RF | SMB | HML | RF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||
| 2023-10 | -11.8200 | -8.0400 | -5.4700 | -4.4900 | -5.6900 | -4.9900 | -4.7800 | -6.1700 | -6.4800 | -8.7700 | -3.1900 | -3.8700 | 0.1900 | 0.4700 |
| 2023-11 | 7.8000 | 8.7100 | 7.1900 | 8.1500 | 7.7400 | 5.3800 | 8.0100 | 9.9700 | 10.4500 | 12.3300 | 8.8400 | -0.0200 | 1.6400 | 0.4400 |
| 2023-12 | 14.9500 | 13.2800 | 14.0100 | 11.9000 | 10.5300 | 9.3300 | 6.5900 | 6.7600 | 8.4100 | 13.2100 | 4.8700 | 6.3400 | 4.9300 | 0.4300 |
| 2024-01 | -6.8900 | -5.0200 | -3.9900 | -2.2500 | -2.3300 | -2.4100 | -0.9400 | 0.0400 | -0.3900 | -0.6600 | 0.7100 | -5.0900 | -2.3800 | 0.4700 |
| 2024-02 | 8.2200 | 3.9100 | 2.6200 | 2.4500 | 2.0900 | 3.8600 | 4.3500 | 5.4000 | 6.0200 | 10.5000 | 5.0600 | -0.2400 | -3.4800 | 0.4200 |
ports = df_mom.columns.to_list()[:10]mods = [
smf.ols(formula=f'I(Q("{p}") - RF) ~ Q("Mkt-RF")', data=df_mom.loc[:'1980'])
for
p in ports
]fits = [m.fit() for m in mods]params = (
pd.concat([f.params for f in fits], axis=1, keys=ports, names='Portolio')
.transpose()
)bses = (
pd.concat([f.bse for f in fits], axis=1, keys=ports, names='Portfolio')
.transpose()
)start = df_mom.loc[:'1980'].index[0].to_timestamp()
stop = df_mom.loc[:'1980'].index[-1].to_timestamp()
params['Intercept'].plot(kind='bar', yerr=bses['Intercept'])
plt.ylabel(r'Monthly CAPM $\alpha$ (%)')
plt.title(
r'Momentum Portfolio Monthly CAPM $\alpha$s' +
'\n' +
f'from {start:%b %Y} through {stop:%b %Y}'
)
plt.show()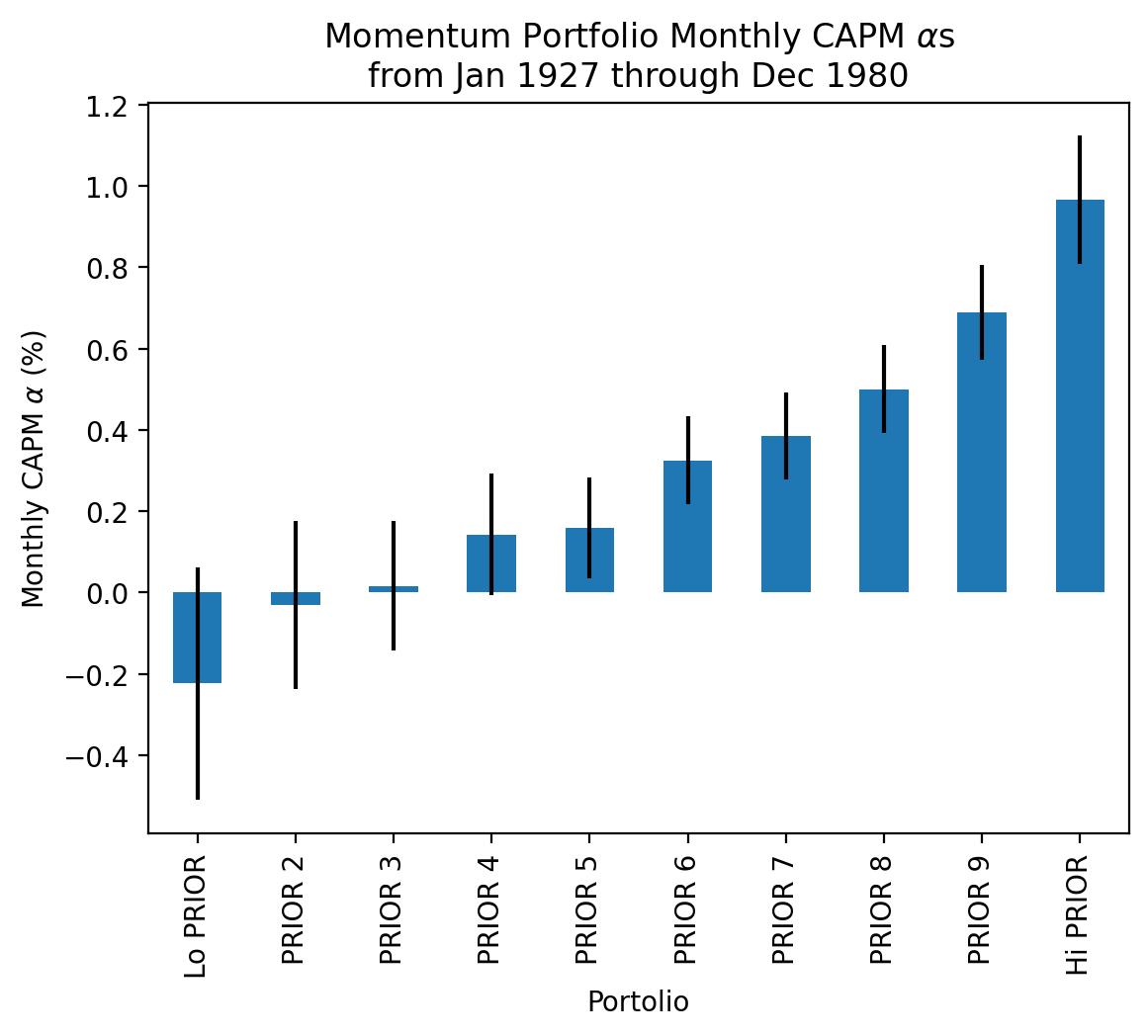
ff_mom = pdr.DataReader(
name='F-F_Momentum_Factor',
data_source='famafrench',
start='1900'
)
ff_mom[0].columns = [c.strip() for c in ff_mom[0].columns]
ff_mom[0].tail()C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1313848978.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\1313848978.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
ff_mom = pdr.DataReader(| Mom | |
|---|---|
| Date | |
| 2023-10 | 1.7300 |
| 2023-11 | 2.7500 |
| 2023-12 | -5.5100 |
| 2024-01 | 5.1800 |
| 2024-02 | 4.9200 |
df_mom_3 = (
ff_m[0].join(ff_mom[0])
[['Mkt-RF', 'Mom']]
.stack()
.rename_axis(index=['Date', 'Factor'])
.to_frame('Return')
.reset_index()
.assign(Decade=lambda x: (x['Date'].dt.year // 10 ) * 10)
)sns.barplot(
data=df_mom_3,
x='Decade',
y='Return',
hue='Factor'
)
plt.ylabel('Annualized Mean of Monthly Returns (%)')
plt.title('Comparison on Market and Value Stock Risk Premia')
plt.show()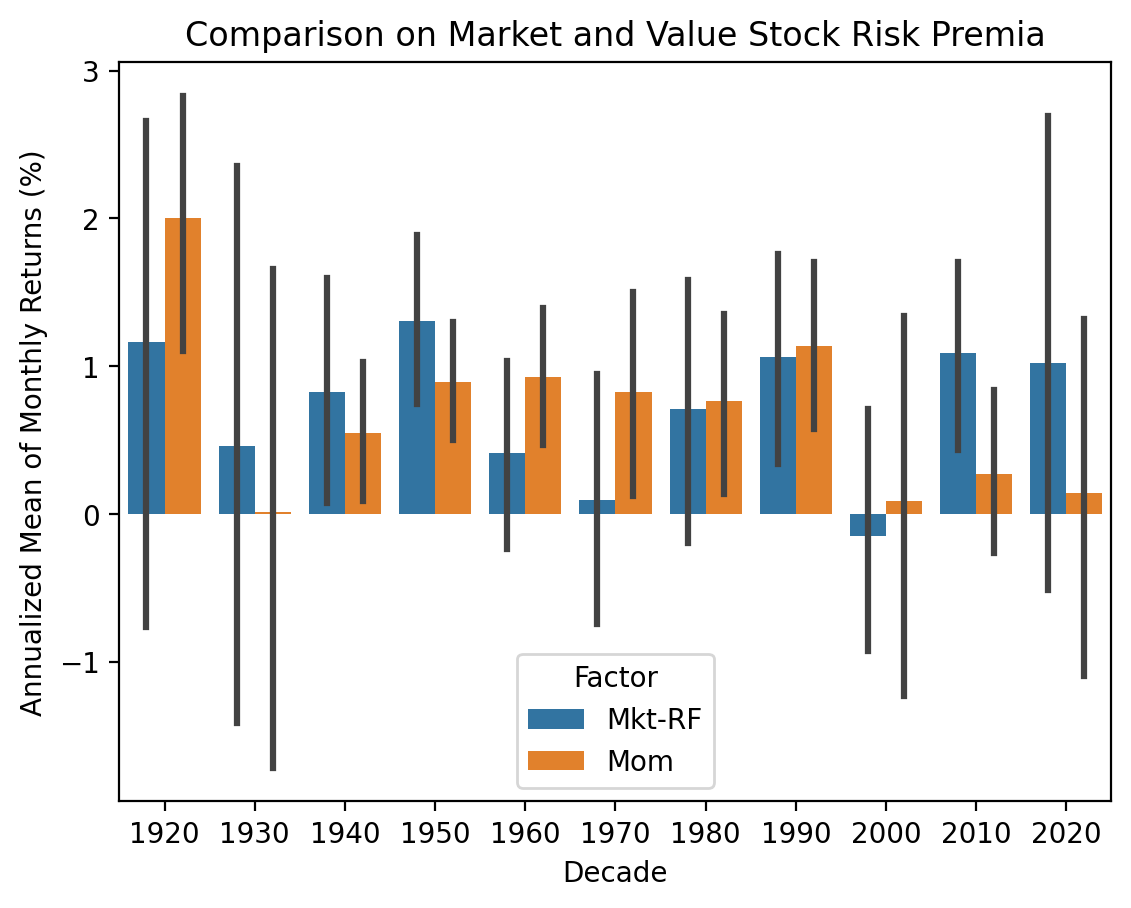
3.8 Plot the coefficient estimates from a rolling Fama-French three-factor model for Berkshire Hathaway
Use a three-year window with daily returns. How has Buffett’s \(\alpha\) and \(\beta\)s changed over the past four decades?
brk = (
yf.download(tickers='BRK-A')
.iloc[:-1]
.rename_axis(columns=['Variable'])
.assign(r=lambda x: x['Adj Close'].pct_change().mul(100))
.dropna()
.join(
pdr.DataReader(
name='F-F_Research_Data_Factors_daily',
data_source='famafrench',
start='1900'
)[0],
how='inner'
)
)[*********************100%%**********************] 1 of 1 completed
C:\Users\r.herron\AppData\Local\Temp\ipykernel_27860\2930704642.py:8: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(from statsmodels.regression.rolling import RollingOLScoefs = (
RollingOLS.from_formula(
formula='I(r-RF) ~ Q("Mkt-RF") + SMB + HML',
data=brk,
window=3*252
)
.fit()
.params
.rename_axis(columns='Coefficient')
.rename(columns={'Q("Mkt-RF")': 'Mkt-RF'})
)fig, ax = plt.subplots(2, 1, sharex=True)
coefs['Intercept'].plot(ax=ax[0], legend=True)
coefs.drop('Intercept', axis=1).plot(ax=ax[1])
plt.suptitle(
'Rolling Three-Factor Regressions' +
'\nThree-Year Windows with Daily Returns in Percent'
)
plt.show()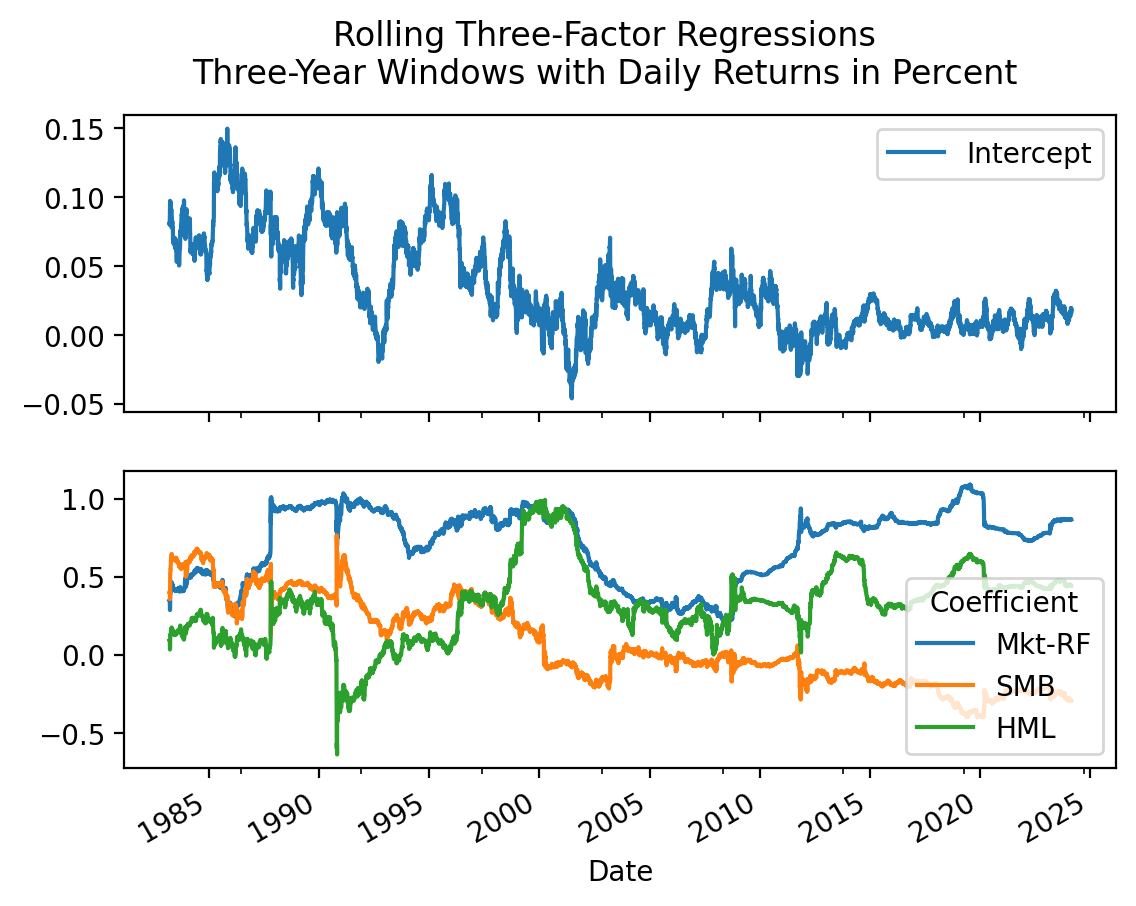
Buffett’s \(\alpha\) was large, but has declined to zero. Also, his loading on SMB (size factor) has gone from positive to negative, indicating that he has moved from small stocks to large stocks as Berkshire Hathaway has grown.