import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pandas_datareader as pdr
import statsmodels.api as sm
import yfinance as yfHerron Topic 2 - Trading Strategies
FINA 6333 for Spring 2024
This notebook covers trading strategies based on technical analysis in three parts:
- What is technical analysis?
- Why might trading strategies based on technical analysis work (or not work)?
- Implement a simple moving average (SMA) trading strategy
I based this lecture notebook on chapter 12 of Ivo Welch’s Corporate Finance textbook and chapter 2 of Eryk Lewinson’s Python for Finance Cookbook. The practice notebook will cover several other trading strategies based on technical analysis.
%precision 4
pd.options.display.float_format = '{:.4f}'.format
%config InlineBackend.figure_format = 'retina'1 What is technical analysis?
Technical analysis is a methodology that analyzes past market data (e.g., past prices and volume) in an attempt to forecast future price movements. If technical analysis can predict future price movements, the market is not weak-form efficient. Ivo Welch provides the three degrees of market efficiency in section 12.2 of chapter 12 of his (free) Corporate Finance textbook:
The Traditional Classification The traditional definition of market efficiency focuses on information. In the traditional classification, market efficiency comes in one of three primary degrees: weak, semi-strong, and strong.
Weak market efficiency says that all information in past prices is reflected in today’s stock prices so that technical analysis (trading based solely on historical price patterns) cannot be used to beat the market. Put differently, the market is the best technical analyst.
Semistrong market efficiency says that all public information is reflected in today’s stock prices, so that neither fundamental trading (based on underlying firm fundamentals, such as cash flows or discount rates) nor technical analysis can be used to beat the market. Put differently, the market is both the best technical and the best fundamental analyst.
Strong market efficiency says that all information, both public and private, is reflected in today’s stock prices, so that nothing — not even private insider information — can be used to beat the market. Put differently, the market is the best analyst and cannot be beat.
In this traditional classification, all finance professors nowadays believe that most U.S. financial markets are not strong-form efficient: Insider trading may be illegal, but it works. However, there are still arguments as to which markets are only semi-strong-form efficient or even only weak-form efficient.
Section 12.2 goes on to provide Welch’s own taxonomy of true, firm, mild, and nonbelievers in market efficiency. Chapter 12 summarizes market efficiency, classical finance, behavioral finance, arbitrage, limits to arbitrage, and their consequences for managers and investors. We will focus on technical analysis in this notebook, but chapter 12 is excellent.
2 Why might trading strategies based on technical analysis work or not?
2.1 …Work?
Technical analysis relies on a few ideas:
- Market prices and volume reflect all relevant information, so we can focus on past prices and volume instead of fundamentals and news.
- Market prices move in trends and patterns driven by market participants.
- These trends and patterns tend to repeat themselves because market participants create them.
2.2 …Or Not?
The logic above is reasonable. However, if past market prices reflect all relevant information, they should also reflect any prices trends they predict. Therefore, any patterns should be self-defeating, and market prices should follow a random walk. As well, the signal-to-noise ratio in market prices is high! Still, technical analysis provides an opportunity to learn how to implement and back-test trading strategies in Python.
2.2.1 A Random Walk
In a random walk, the price tomorrow equals the price today plus a tiny drift plus noise. In math terms, a random walk is \[P_{t} = \rho P_{t-1} + m P_{t-1} + \varepsilon_t\] where \(m\) is a small drift term and \(E[\varepsilon] = 0\). If \(\rho > 1\), prices would quickly increase, and, if \(\rho < 1\), prices would quickly decrease. Let us examine the historical record.
ff = (
pdr.DataReader(
name='F-F_Research_Data_Factors_daily',
data_source='famafrench',
start='1900'
)
[0]
.assign(Mkt=lambda x: x['Mkt-RF'] + x['RF'])
.div(100)
)
ff.head()C:\Users\r.herron\AppData\Local\Temp\ipykernel_22728\2916005334.py:2: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
pdr.DataReader(| Mkt-RF | SMB | HML | RF | Mkt | |
|---|---|---|---|---|---|
| Date | |||||
| 1926-07-01 | 0.0010 | -0.0025 | -0.0027 | 0.0001 | 0.0011 |
| 1926-07-02 | 0.0045 | -0.0033 | -0.0006 | 0.0001 | 0.0046 |
| 1926-07-06 | 0.0017 | 0.0030 | -0.0039 | 0.0001 | 0.0018 |
| 1926-07-07 | 0.0009 | -0.0058 | 0.0002 | 0.0001 | 0.0010 |
| 1926-07-08 | 0.0021 | -0.0038 | 0.0019 | 0.0001 | 0.0022 |
We can use market returns to impute market prices relative to the last day of June 1926.
price = ff['Mkt'].add(1).cumprod()
price.tail()Date
2024-01-25 11969.2170
2024-01-26 11969.4564
2024-01-29 12073.8301
2024-01-30 12060.7903
2024-01-31 11853.5860
Name: Mkt, dtype: float64price.plot()
plt.title('Imputed Market Prices\nAssuming $1 on the Last Day of June 1926')
plt.ylabel('Imputed Market Price ($)')
plt.semilogy()
plt.show()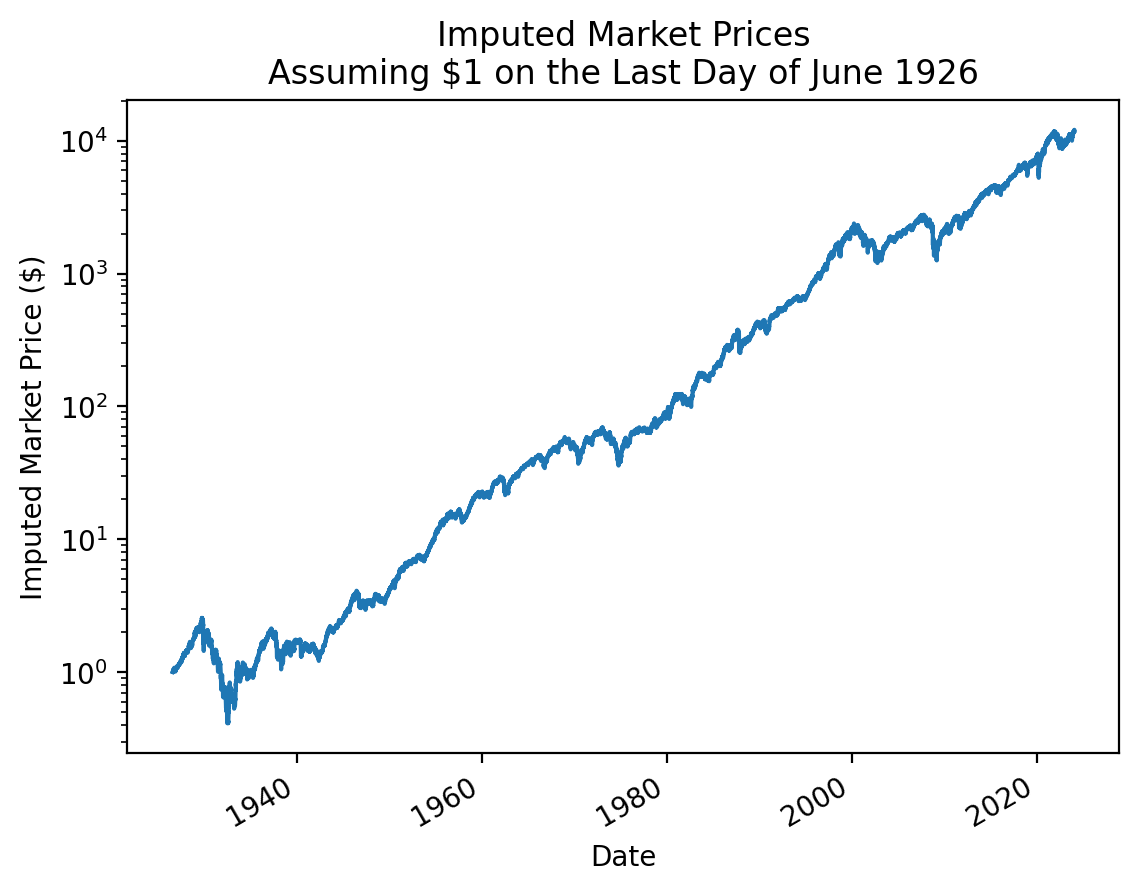
We need lagged prices to estimate \(\rho\). We will add 10 lags of \(P\) to help us understand the relation between past and future prices.
price_lags = (
pd.concat(
objs=[price.shift(t) for t in range(11)],
keys=[f'Lag {t}' for t in range(11)],
names=['Price'],
axis=1,
)
)
price_lags.head()| Price | Lag 0 | Lag 1 | Lag 2 | Lag 3 | Lag 4 | Lag 5 | Lag 6 | Lag 7 | Lag 8 | Lag 9 | Lag 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||
| 1926-07-01 | 1.0011 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1926-07-02 | 1.0057 | 1.0011 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1926-07-06 | 1.0075 | 1.0057 | 1.0011 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1926-07-07 | 1.0085 | 1.0075 | 1.0057 | 1.0011 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1926-07-08 | 1.0107 | 1.0085 | 1.0075 | 1.0057 | 1.0011 | NaN | NaN | NaN | NaN | NaN | NaN |
(
price_lags
.dropna()
.corr()
.loc['Lag 0']
.plot(kind='bar')
)
plt.title('Correlations with Imputed Market Price')
plt.ylabel('Correlation')
plt.show()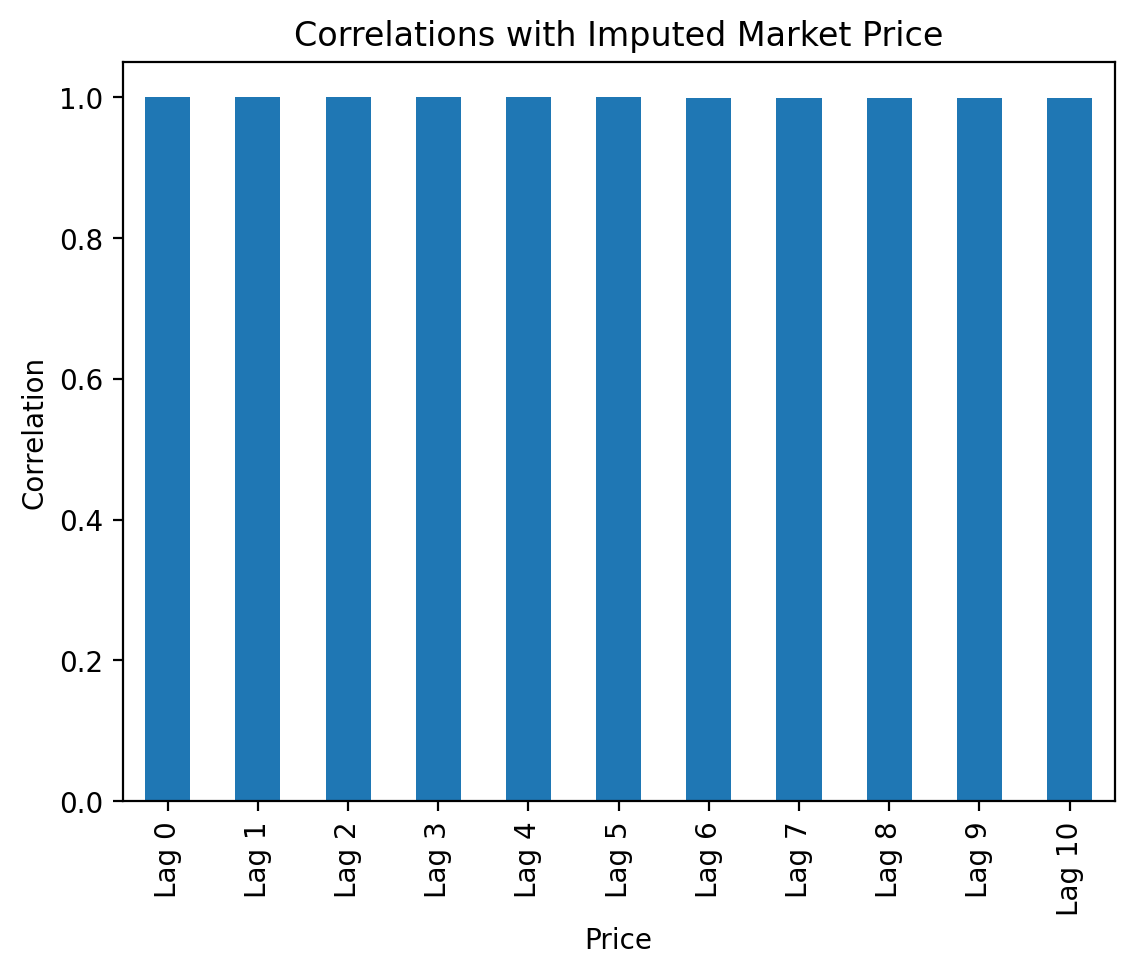
But these are pairwise correlations. If we estimate conditional correlations, we see that most of the price information is in the first lag!
_ = price_lags.dropna()
y = _['Lag 0']
X = _.drop('Lag 0', axis=1).pipe(sm.add_constant)
model = sm.OLS(endog=y, exog=X)
fit = model.fit(cov_type='HAC', cov_kwds={'maxlags': 10})
fit.summary()| Dep. Variable: | Lag 0 | R-squared: | 1.000 |
| Model: | OLS | Adj. R-squared: | 1.000 |
| Method: | Least Squares | F-statistic: | 1.848e+06 |
| Date: | Fri, 15 Mar 2024 | Prob (F-statistic): | 0.00 |
| Time: | 11:16:38 | Log-Likelihood: | -1.2242e+05 |
| No. Observations: | 25660 | AIC: | 2.449e+05 |
| Df Residuals: | 25649 | BIC: | 2.450e+05 |
| Df Model: | 10 | ||
| Covariance Type: | HAC |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
| const | 0.0590 | 0.143 | 0.412 | 0.680 | -0.222 | 0.340 |
| Lag 1 | 0.9473 | 0.035 | 27.080 | 0.000 | 0.879 | 1.016 |
| Lag 2 | 0.0778 | 0.060 | 1.287 | 0.198 | -0.041 | 0.196 |
| Lag 3 | -0.0342 | 0.038 | -0.897 | 0.369 | -0.109 | 0.041 |
| Lag 4 | -0.0275 | 0.043 | -0.642 | 0.521 | -0.112 | 0.057 |
| Lag 5 | 0.0442 | 0.040 | 1.108 | 0.268 | -0.034 | 0.122 |
| Lag 6 | -0.0657 | 0.043 | -1.539 | 0.124 | -0.149 | 0.018 |
| Lag 7 | 0.1271 | 0.050 | 2.541 | 0.011 | 0.029 | 0.225 |
| Lag 8 | -0.1299 | 0.056 | -2.315 | 0.021 | -0.240 | -0.020 |
| Lag 9 | 0.1485 | 0.048 | 3.095 | 0.002 | 0.054 | 0.242 |
| Lag 10 | -0.0871 | 0.032 | -2.705 | 0.007 | -0.150 | -0.024 |
| Omnibus: | 15996.444 | Durbin-Watson: | 1.993 |
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 4983693.037 |
| Skew: | -1.823 | Prob(JB): | 0.00 |
| Kurtosis: | 71.176 | Cond. No. | 8.90e+03 |
Notes:
[1] Standard Errors are heteroscedasticity and autocorrelation robust (HAC) using 10 lags and without small sample correction
[2] The condition number is large, 8.9e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
plt.bar(
x=price_lags.columns[1:],
height=fit.params[1:],
yerr=2*fit.bse[1:]
)
plt.title('Conditional Correlations with Imputed Market Price\nBars Indicate Plus-or-Minus Standard Errors')
plt.ylabel('Conditional Correlation')
plt.xlabel('Price')
plt.show()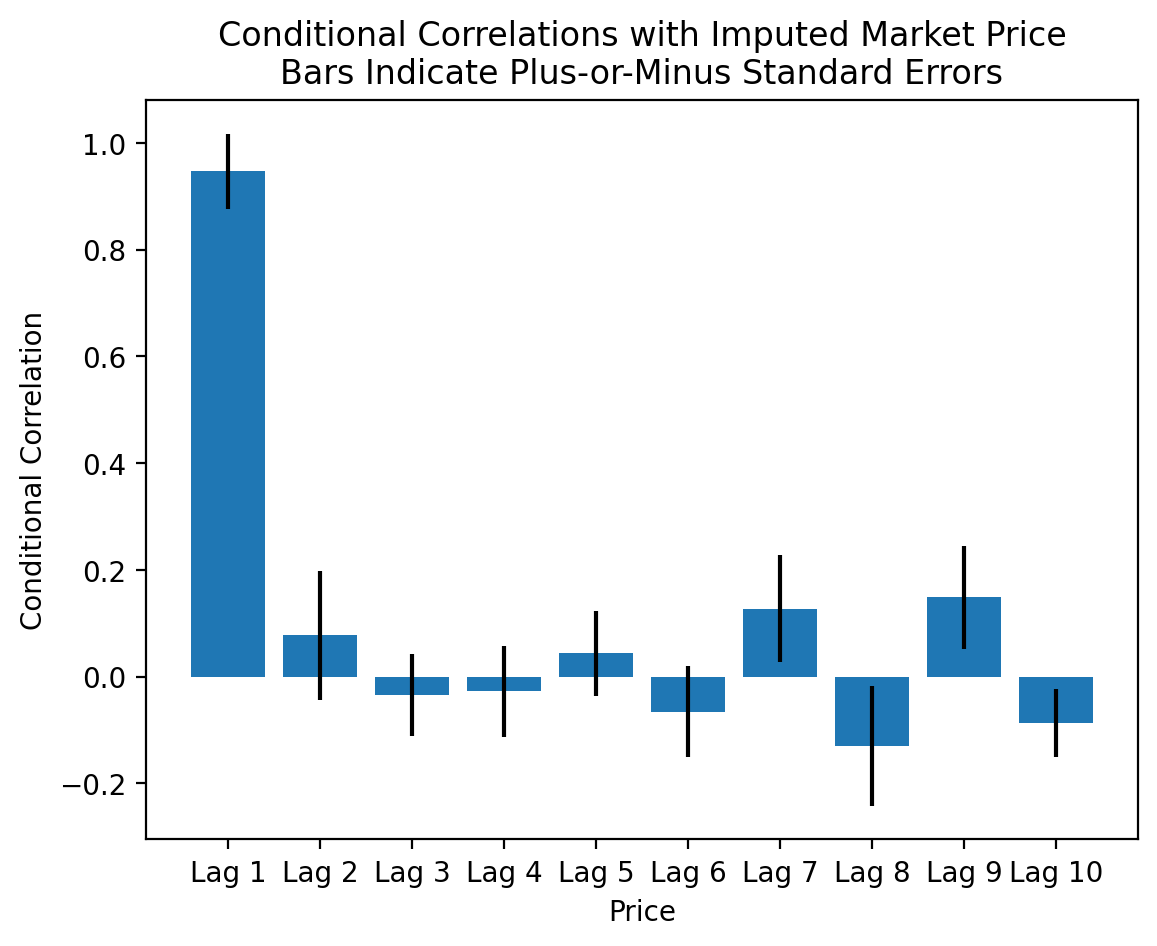
2.2.2 Signal-to-Noise Ratio
Recall, we can express a random walk as \(P_{t} = \rho P_{t-1} + m P_{t-1} + \varepsilon_t\). Since \(\rho = 1\), we can subtract \(P_{t-1}\) from both sides, then divide by \(P_{t-1}\) on both sides. This transformation expresses a random walk in terms of returns: \(r_{t-1,t} = m + e_t\), where \(E[e_t] = 0\) and \(SD[e_t] = s\), so \(E[r_{t-1, t}] = m\). We can think of the signal-to-noise ratio as \(\frac{m}{s}\). How high is this ratio?
m, s = ff['Mkt'].mean(), ff['Mkt'].std()Here \(m\) is about 4 basis points per day!
m0.0004However, \(s\) is about 108 basis points per day!
s0.0108Therefore, the signal-to-noise ratio is less than 4 percent!
m/s0.0392Recall that means grow linearly with time and standard deviations growth with the square-root of time. So, if we want \(\sqrt{t} \times \frac{m}{s} \geq 2\), we need \(t \geq \left(2 \times \frac{s}{m} \right)^2\) days! Even with market portfolio noise, which is diversified and low, we needat least a decade! During this decade, the true values of \(m\) and \(s\) can change!
(2 * s / m)**2 / 25210.30883 Implement a simple moving average (SMA) trading strategy
The goal of technical analysis is to “buy low, and sell high.” The \(n\)-day SMA reduces noise in market prices, removing market fluctuations and providing estimates of “true” prices. While the market price is above the SMA, the SMA rises. While the market price is below the SMA, the SMA falls. So, if we buy the stock as it cross the SMA from below and sell the stock as it crosses the SMA from above, we mechanically buy low and sell high! Here, we will implement a long-only 20-day SMA (SMA(20)) strategy with Bitcoin:
- Buy when the closing price crosses SMA(20) from below
- Sell when the closing price crosses SMA(20) from above
- No short-selling
Because we will not short sell the stock, we can simplify this strategy to “long if above SMA(20), otherwise neutral”. First, we will need Bitcoin returns data.
btc = (
yf.download(tickers='BTC-USD')
.assign(Return = lambda x: x['Adj Close'].pct_change())
.rename_axis(columns='Variable')
)
btc.head()[*********************100%%**********************] 1 of 1 completed| Variable | Open | High | Low | Close | Adj Close | Volume | Return |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2014-09-17 | 465.8640 | 468.1740 | 452.4220 | 457.3340 | 457.3340 | 21056800 | NaN |
| 2014-09-18 | 456.8600 | 456.8600 | 413.1040 | 424.4400 | 424.4400 | 34483200 | -0.0719 |
| 2014-09-19 | 424.1030 | 427.8350 | 384.5320 | 394.7960 | 394.7960 | 37919700 | -0.0698 |
| 2014-09-20 | 394.6730 | 423.2960 | 389.8830 | 408.9040 | 408.9040 | 36863600 | 0.0357 |
| 2014-09-21 | 408.0850 | 412.4260 | 393.1810 | 398.8210 | 398.8210 | 26580100 | -0.0247 |
Next we:
- Use
.rolling(20).mean()to add aSMA20column containing SMA(20) to ourbtcdata frame - Use
np.select()to add aPositioncolumn containing:1(long) when the adjusted close is greater than SMA(20)0(neutral) when the adjusted close is less than (or equal to) SMA(20)- We could use
np.where()instead ofnp.select(), but usingnp.select()provides a more flexible framework for more complex examples - We use
.shift()to compare yesterday’s closing prices, avoiding a look-ahead bias
- Add a
Strategycolumn containing:ReturnifPosition == 10ifPosition == 0- We could earn the risk-free rate instead of 0 percent, but earning 0 percent simplifies this example
btc = (
btc
.assign(
SMA20 = lambda x: x['Adj Close'].rolling(20).mean(),
Position = lambda x: np.select(
condlist=[x['Adj Close'].shift() > x['SMA20'].shift(), x['Adj Close'].shift() <= x['SMA20'].shift()],
choicelist=[1, 0],
default=np.nan
),
Strategy = lambda x: x['Position'] * x['Return']
)
)
btc.head(30)| Variable | Open | High | Low | Close | Adj Close | Volume | Return | SMA20 | Position | Strategy |
|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||
| 2014-09-17 | 465.8640 | 468.1740 | 452.4220 | 457.3340 | 457.3340 | 21056800 | NaN | NaN | NaN | NaN |
| 2014-09-18 | 456.8600 | 456.8600 | 413.1040 | 424.4400 | 424.4400 | 34483200 | -0.0719 | NaN | NaN | NaN |
| 2014-09-19 | 424.1030 | 427.8350 | 384.5320 | 394.7960 | 394.7960 | 37919700 | -0.0698 | NaN | NaN | NaN |
| 2014-09-20 | 394.6730 | 423.2960 | 389.8830 | 408.9040 | 408.9040 | 36863600 | 0.0357 | NaN | NaN | NaN |
| 2014-09-21 | 408.0850 | 412.4260 | 393.1810 | 398.8210 | 398.8210 | 26580100 | -0.0247 | NaN | NaN | NaN |
| 2014-09-22 | 399.1000 | 406.9160 | 397.1300 | 402.1520 | 402.1520 | 24127600 | 0.0084 | NaN | NaN | NaN |
| 2014-09-23 | 402.0920 | 441.5570 | 396.1970 | 435.7910 | 435.7910 | 45099500 | 0.0836 | NaN | NaN | NaN |
| 2014-09-24 | 435.7510 | 436.1120 | 421.1320 | 423.2050 | 423.2050 | 30627700 | -0.0289 | NaN | NaN | NaN |
| 2014-09-25 | 423.1560 | 423.5200 | 409.4680 | 411.5740 | 411.5740 | 26814400 | -0.0275 | NaN | NaN | NaN |
| 2014-09-26 | 411.4290 | 414.9380 | 400.0090 | 404.4250 | 404.4250 | 21460800 | -0.0174 | NaN | NaN | NaN |
| 2014-09-27 | 403.5560 | 406.6230 | 397.3720 | 399.5200 | 399.5200 | 15029300 | -0.0121 | NaN | NaN | NaN |
| 2014-09-28 | 399.4710 | 401.0170 | 374.3320 | 377.1810 | 377.1810 | 23613300 | -0.0559 | NaN | NaN | NaN |
| 2014-09-29 | 376.9280 | 385.2110 | 372.2400 | 375.4670 | 375.4670 | 32497700 | -0.0045 | NaN | NaN | NaN |
| 2014-09-30 | 376.0880 | 390.9770 | 373.4430 | 386.9440 | 386.9440 | 34707300 | 0.0306 | NaN | NaN | NaN |
| 2014-10-01 | 387.4270 | 391.3790 | 380.7800 | 383.6150 | 383.6150 | 26229400 | -0.0086 | NaN | NaN | NaN |
| 2014-10-02 | 383.9880 | 385.4970 | 372.9460 | 375.0720 | 375.0720 | 21777700 | -0.0223 | NaN | NaN | NaN |
| 2014-10-03 | 375.1810 | 377.6950 | 357.8590 | 359.5120 | 359.5120 | 30901200 | -0.0415 | NaN | NaN | NaN |
| 2014-10-04 | 359.8920 | 364.4870 | 325.8860 | 328.8660 | 328.8660 | 47236500 | -0.0852 | NaN | NaN | NaN |
| 2014-10-05 | 328.9160 | 341.8010 | 289.2960 | 320.5100 | 320.5100 | 83308096 | -0.0254 | NaN | NaN | NaN |
| 2014-10-06 | 320.3890 | 345.1340 | 302.5600 | 330.0790 | 330.0790 | 79011800 | 0.0299 | 389.9104 | NaN | NaN |
| 2014-10-07 | 330.5840 | 339.2470 | 320.4820 | 336.1870 | 336.1870 | 49199900 | 0.0185 | 383.8530 | 0.0000 | 0.0000 |
| 2014-10-08 | 336.1160 | 354.3640 | 327.1880 | 352.9400 | 352.9400 | 54736300 | 0.0498 | 380.2780 | 0.0000 | 0.0000 |
| 2014-10-09 | 352.7480 | 382.7260 | 347.6870 | 365.0260 | 365.0260 | 83641104 | 0.0342 | 378.7895 | 0.0000 | 0.0000 |
| 2014-10-10 | 364.6870 | 375.0670 | 352.9630 | 361.5620 | 361.5620 | 43665700 | -0.0095 | 376.4225 | 0.0000 | -0.0000 |
| 2014-10-11 | 361.3620 | 367.1910 | 355.9510 | 362.2990 | 362.2990 | 13345200 | 0.0020 | 374.5964 | 0.0000 | 0.0000 |
| 2014-10-12 | 362.6060 | 379.4330 | 356.1440 | 378.5490 | 378.5490 | 17552800 | 0.0449 | 373.4162 | 0.0000 | 0.0000 |
| 2014-10-13 | 377.9210 | 397.2260 | 368.8970 | 390.4140 | 390.4140 | 35221400 | 0.0313 | 371.1474 | 1.0000 | 0.0313 |
| 2014-10-14 | 391.6920 | 411.6980 | 391.3240 | 400.8700 | 400.8700 | 38491500 | 0.0268 | 370.0306 | 1.0000 | 0.0268 |
| 2014-10-15 | 400.9550 | 402.2270 | 388.7660 | 394.7730 | 394.7730 | 25267100 | -0.0152 | 369.1906 | 1.0000 | -0.0152 |
| 2014-10-16 | 394.5180 | 398.8070 | 373.0700 | 382.5560 | 382.5560 | 26990000 | -0.0309 | 368.0971 | 1.0000 | -0.0309 |
I find it helpful to plot Adj Close, SMA20, and Position for a sort window with one or more crossings.
fig, ax = plt.subplots(2, 1, sharex=True)
_ = btc.loc['2023-02'].iloc[-15:]
_[['Adj Close', 'SMA20']].plot(ax=ax[0], ylabel='BTC-USD ($)')
_[['Position']].plot(ax=ax[1], ylabel='Position', legend=False)
plt.suptitle('Bitcoin SMA(20) Strategy')
plt.show()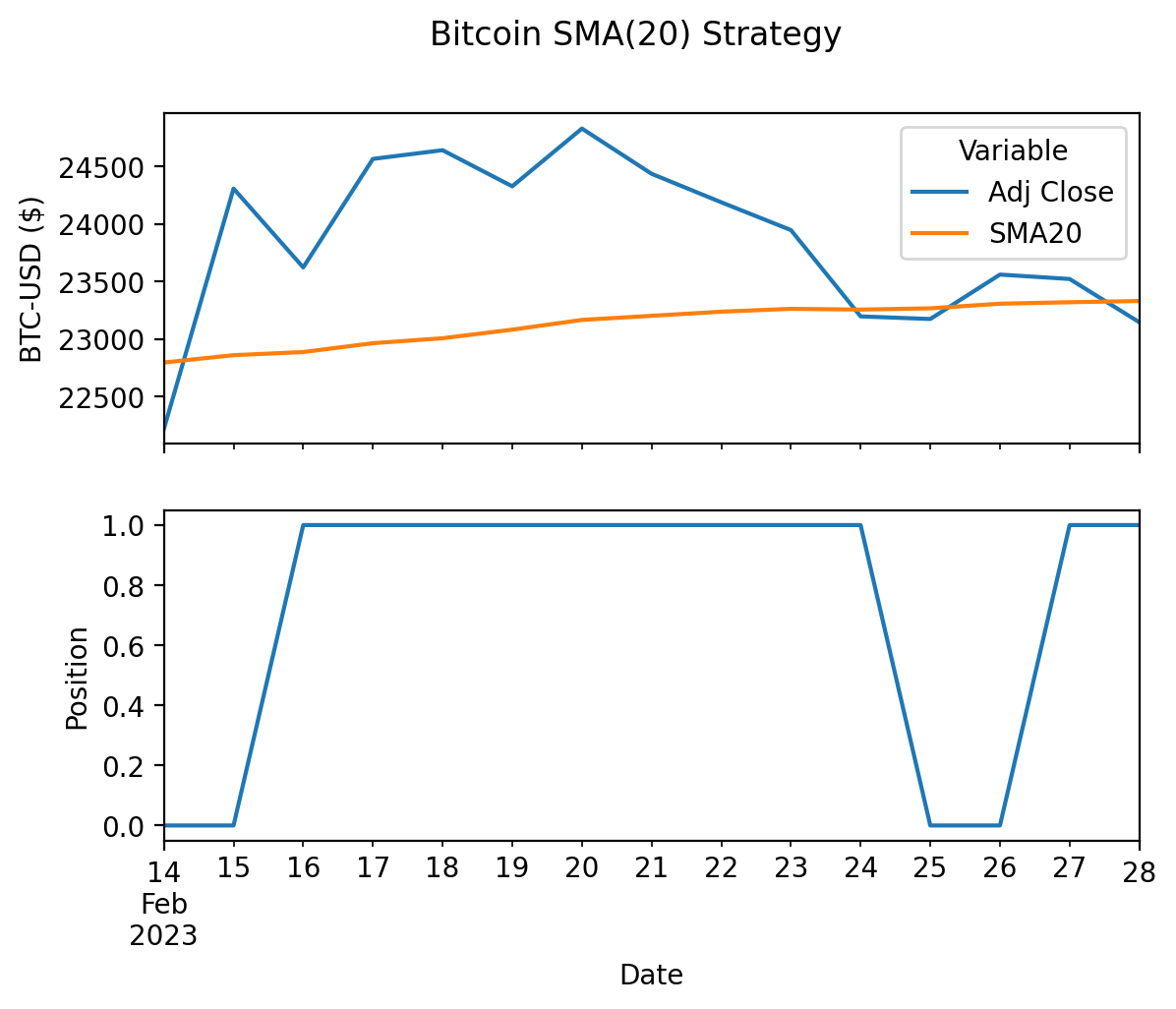
We can compare the long-run performance of buy-and-hold and SMA(20).
_ = btc[['Return', 'Strategy']].dropna()
(
_
.add(1)
.cumprod()
.rename_axis(columns='Strategy')
.rename(columns={'Return': 'Buy-And-Hold', 'Strategy': 'SMA(20)'})
.plot()
)
plt.ylabel('Value ($)')
plt.title(f'Value of $1 Invested at Close on {_.index[0] - pd.offsets.Day(1):%B %d, %Y}')
plt.show()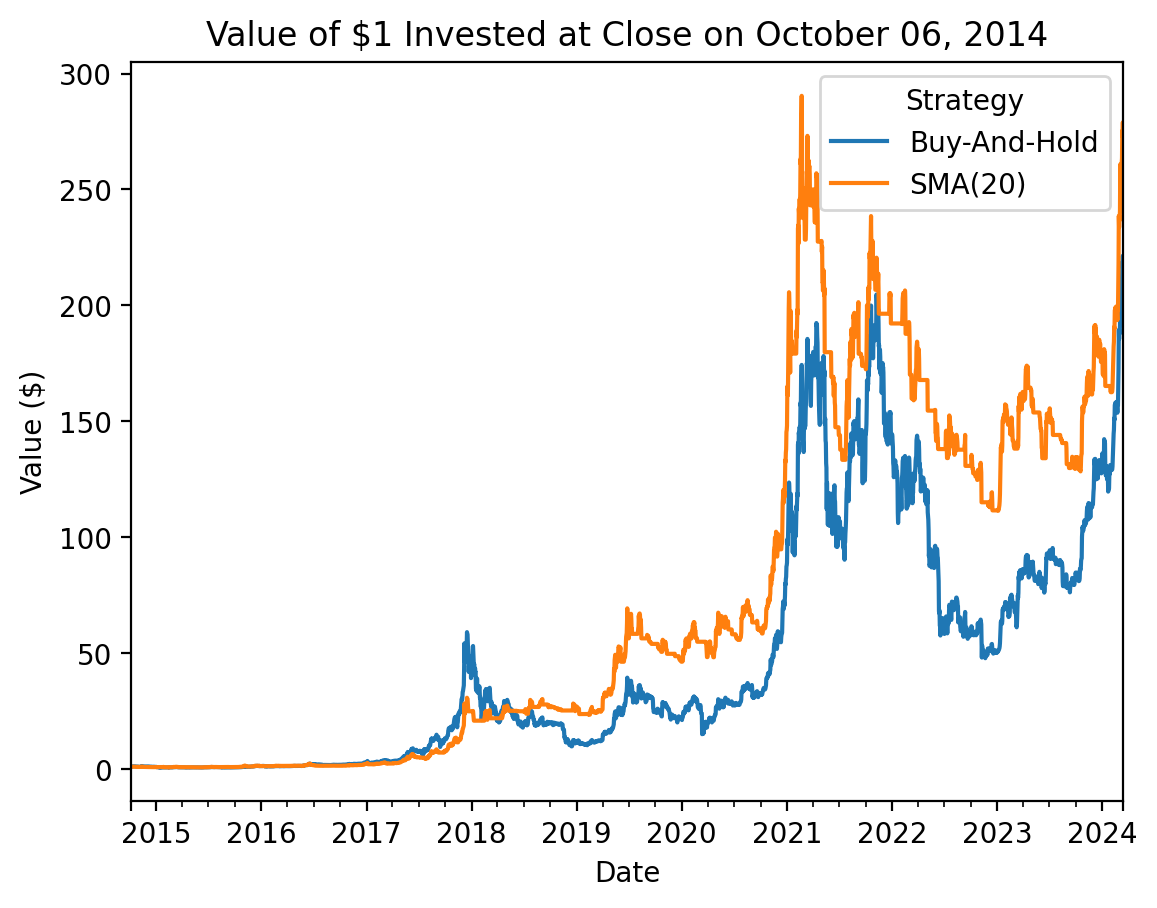
In the practice notebook, we will dig deeper on this strategy and others.